types2: Exploring word-frequency differences in corpora
This is the authors’ version of the paper that was published in Big and Rich Data in English Corpus Linguistics, Methods and Explorations, volume 19 of Studies in Variation, Contacts and Change in English, 2017.
Abstract
We demonstrate the use of the types2 tool to explore, visualize, and assess the significance of variation in word frequencies. Based on accumulation curves and the statistical technique of permutation testing, this freely available tool is especially well suited to the study of types and hapax legomena, which are common measures of morphological productivity and lexical diversity. We have developed a new version of the tool that provides improved linking between the visualizations, metadata, and corpus texts, which facilitates the analysis of rich data.
The new version of our tool is demonstrated using two data sets extracted from the Corpora of Early English Correspondence (CEEC) and the British National Corpus (BNC), both of which are rich in sociolinguistic metadata. We show how to use our software to analyse such data sets, and how the new version of our tool can turn the results into interactive web pages with visualizations that are linked to the underlying data and metadata. Our paper illustrates how the linked data facilitates exploring and interpreting the results.
Contents
Introduction
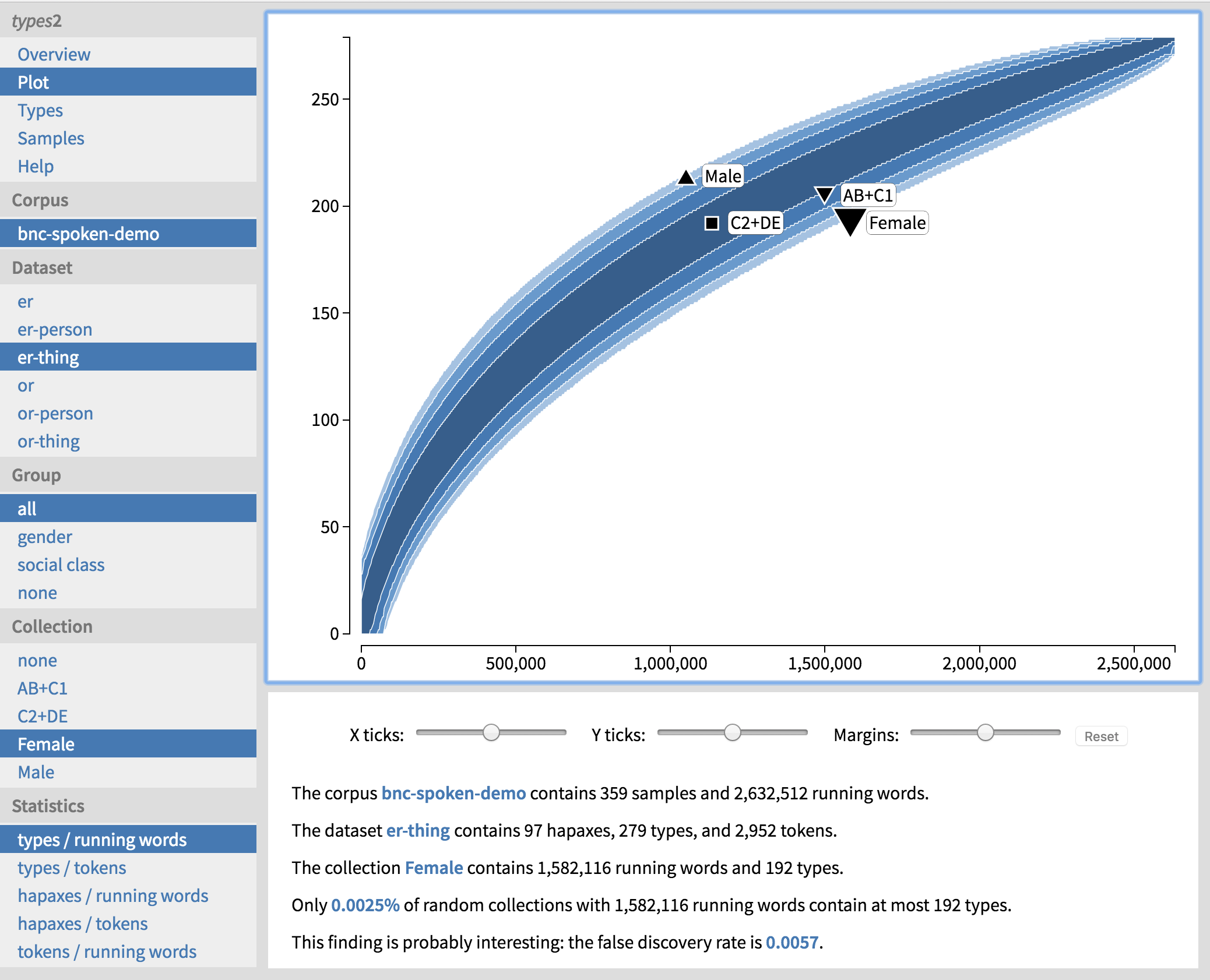
This paper demonstrates the use of types2 (Suomela 2016), a freely available corpus tool for comparing the frequencies of tokens, types, and hapax legomena across subcorpora. The tool uses accumulation curves and the statistical technique of permutation testing to compare the subcorpora with a “typical” corpus of a similar size, in order to visualize the frequencies and to identify statistically significant findings. The new version of the tool makes it easy to explore the results with the help of an interactive web user interface that provides direct access to relevant findings, visualizations, metadata, and corpus texts (Figure 1). This paper is accompanied by a live version of the interactive tool – all screenshots are direct links to the web user interface – and the tools and input files described in this work are also freely available for download. While the two case studies presented here focus on sociolinguistic variation in morphological productivity, types2 can also be used to study e.g. genre variation or change over time in the frequencies of any words of interest to the user.
Comparing word frequencies
Comparing word frequencies is an essential part of corpus linguistics. One of the issues in word-frequency comparisons is whether the difference observed is statistically significant. Traditionally, significance testing in corpus linguistics has been handled using a model that is less than ideal: the bag-of-words model, which assumes that the occurrences of words are independent of each other, which is obviously untrue and leads to overestimated significance (Kilgarriff 2005, Bestgen 2014). Bag-of-words tests include the chi-square test, Fisher’s exact test, and the log-likelihood ratio test.
Nowadays, many are moving away from this inappropriate model towards tests that make the more reasonable assumption that words occurring in different texts are independent of each other (Lijffijt et al. 2012, 2016; Brezina & Meyerhoff 2014). These tests, also known as dispersion-aware tests, include the t-test, the Wilcoxon rank-sum test, and tests based on the statistical technique of resampling (Säily 2014: 46–49, 243–245). Our tool uses a variant of resampling called permutation testing (Dwass 1957). It has the advantage that it can be used to compare type frequencies, which depend on the size of the corpus in a non-linear manner, precluding the use of normalized frequencies that are easy to compare.
Another issue in comparing word frequencies is that of multiple hypothesis testing. Significance tests only estimate the probability that we are wrong in rejecting a single null hypothesis, but in corpus linguistics, we are typically interested in testing multiple hypotheses, such as comparing word frequencies across multiple time periods or social groups. The more hypotheses we test, the greater the likelihood that some of them may be flagged as significant by chance. To resolve this issue, our tool controls the false discovery rate (FDR), or the expected proportion of false positives out of all positives (Benjamini & Hochberg 1995). In practice, this means that as we test more hypotheses, our significance levels become stricter: p < 0.05 is no longer enough, and we may need to go as low as p < 0.0001 or even lower, depending on the FDR we choose as acceptable (see further Section 2.1 below).
For more discussion of these important methodological issues in corpus linguistics, see Säily (2014: 44–51).
Exploring word frequencies
Corpus linguists need context. We are not only interested in comparing word frequencies in the abstract, but also in exploring the word-frequency differences observed in order to generate hypotheses and interpretations. Most of our current tools do not make this easy, as the tables and figures representing the results are typically static and there are no links between the visualizations, statistical analyses, metadata and corpus texts. Research in information visualization has shown that interaction is the key to insight (Pike et al. 2009). The new version of our types2 tool provides an online interface with interactive figures and linked data to facilitate exploration and interpretation. With types2, we can easily move between tables and figures of results, the words themselves, the words in context, and the people who produced the words. We can also filter the views based on corpus metadata, such as genre or social group.
To get to this point, we first need to do a corpus search using a tool such as BNCweb (Hoffmann et al. 2008) or WordSmith Tools (Scott 2016). Then we go through the hits and narrow them down to relevant ones only, for instance in Excel. The input for types2 consists of the relevant hits and the corpus metadata, both in a tabular format. As output, the tool then produces the results in several different formats, including web pages like the one in Figure 1 above. Let us take an example.
Case study: BNC, -er, and -or
Our first example focuses on an extremely productive nominal suffix, -er, which is typically used to derive agentive or instrumental nouns from verbs (e.g. write : writer), and its Latinate variant, -or (Plag 2003: 89; Bauer 2001: 199–203). Our research question is whether there is sociolinguistic variation in the productivity of these suffixes in present-day English. Because -er is a default suffix that attaches “indiscriminately” to all sorts of bases (Bauer et al. 2013: 217, 232), we might expect to find no sociolinguistic variation in its use. On the other hand, previous research has discovered some sociolinguistic variation in the use of the similarly highly productive suffix -ness (Säily 2011), so the issue may not be so clear-cut.
Measuring morphological productivity
We measure morphological productivity in two basic ways: type frequency, or the number of different words containing the suffix under study, and hapax frequency, or the number of words containing the suffix that occur only once in the corpus. Type frequency represents the extent of use or realized productivity of the suffix, while hapax-based measures are seen to predict future productivity, or the “statistically determinable readiness with which an element enters into new combinations” (Bolinger 1948: 18; Baayen 2009).
Säily (2011) shows that hapax-based measures are unusable in small corpora, which is problematic as the measure of type frequency could simply reflect lexical richness rather than morphological productivity (Cowie & Dalton-Puffer 2002: 416). However, as noted by Säily (2014: 238–239), in diachronic studies the aspect of new formations can be taken into account by analysing change in realised productivity. Moreover, new or productive formations can be studied e.g. by only counting those types that have an extant base or those that occur within, say, 50 years of their first attestation date in the Oxford English Dictionary (Cowie & Dalton-Puffer 2002: 419). In previous work (Säily 2008, 2011), these kinds of restrictions have not had a major impact on the results, so the case studies in the present paper will include all types that etymologically contain the suffix in question. This approach is also recommended by Plag (1999: 29), who points out that excluding “non-productive formations” could mean pre-judging the issue of whether the suffix is productive (see further Säily & Suomela 2009: 89–90).
As noted in Section 1.1, type frequencies cannot be normalized, so comparing the numbers of types or hapax legomena produced by different social groups is difficult unless the subcorpora representing the groups are of equal size. Our solution to this is Monte Carlo permutation testing. Rather than trying to compare subcorpora of different sizes with each other, we compare each subcorpus with multiple randomly composed subcorpora of the same size.
The idea behind permutation testing is as follows. First we divide the corpus into samples that are large enough to preserve discourse structure (e.g. individual texts). Then we repeatedly choose a large number of random permutations (i.e. random re-orderings) of the samples. For each random permutation, we can then trace a type accumulation curve: we process the randomly re-ordered corpus and after each sample we calculate how many different types and how many running words we have accumulated so far. This will typically result in a banana-shaped plot similar to the one in Figure 2.
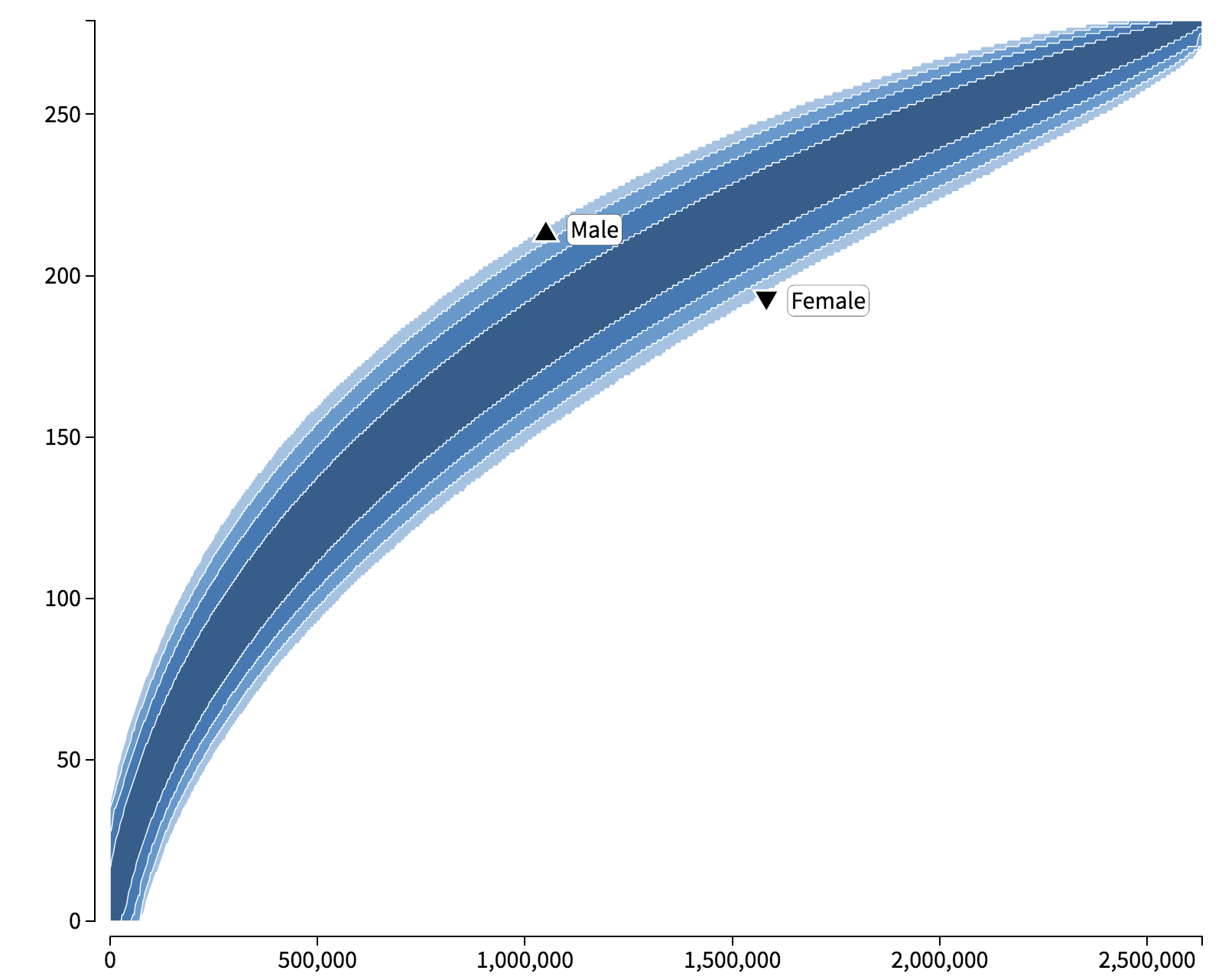
For any single random permutation, the idiosyncrasies of individual speakers may heavily influence the shape of the curve. However, by going through a large number of random permutations, we can learn what the typical shape of the type accumulation curve is, and how much variation there is from one random permutation to another. This is indicated through the shaded areas in Figure 2: most type accumulation curves lie somewhere within the darkest areas, and very few random permutations result in values outside the areas.
In essence, the dark area now identifies the region in which a randomly chosen subcorpus (a randomly chosen subset of samples) would typically fall. Now we can directly compare a subcorpus of a certain social group with a typical random subcorpus (see the triangles in Figure 2). If, under the null hypothesis, the social factor is not connected to the type frequency, then we would expect the subcorpus to reside inside the shaded area. However, if we discover that a subcorpus lies outside this region, then we will have a good reason to reject the null hypothesis: the type frequency is so high or low in comparison with random subcorpora of a similar size that we cannot explain it by mere random chance. The fraction of random permutations that result in equally high or low type frequencies will also directly give us a p-value: for example, if we are testing the hypothesis that women use the suffix -er less productively than men, and we learn that only 1/1000 of the random permutations result in equally low type frequencies for the same number of running words, we have a significant finding at p = 0.001 (see further Säily & Suomela 2009).
As we are interested in studying a large number of different social groups, we are, in essence, testing a large number of hypotheses. If we simply tested each individual hypothesis at some fixed level (e.g. p < 0.05), the vast majority of the discoveries might be false positives. To ensure that only a small fraction of the discoveries are false positives, we will control the false discovery rate (FDR). In this work, we will use a threshold of FDR ≈ 0.1: in essence, we will expect that in each study, more than 90% of the discoveries are true positives and less than 10% of the discoveries are false positives.
In practice, with FDR control in place, we will need to obtain very low p-values for each individual hypothesis in order to reject the null hypothesis. Even if we are dealing with a true phenomenon, this poses the additional challenge of estimating very small probabilities accurately in Monte Carlo testing. We tackle this simply by choosing a sufficiently large number of permutations: For visualisation purposes (e.g. drawing the curves that we see in Figure 2), c. 1 million permutations are typically sufficient. To estimate the p-values, we will typically use c. 10 million permutations.
Data and procedure
Our material consists of the demographically sampled spoken component of the British National Corpus (BNC), which provides conversational data from the early 1990s along with social metadata on the informants. Both gender and social class have been recorded for 358 speakers, who have uttered a total of c. 2.6 million words. Even if it is getting rather old, the corpus is still an excellent source for sociolinguistic studies of British English. A new version, called Spoken BNC2014, is currently being compiled in a collaborative effort by Lancaster University and Cambridge University Press.
To access the corpus, we use the BNCweb interface hosted by Lancaster University. This has the advantage of providing access to some of the audio recordings on which the corpus is based, which is very useful for checking the search results. To analyse and annotate the results further, we export them into Excel.
Another useful resource is MorphoQuantics (Laws & Ryder 2014a, 2014b), which provides lists of types and their frequencies for hundreds of affixes in the spoken component of the BNC. Thanks to this resource, we know which words ending in -er and -or in the BNC represent genuine instances of the suffixes, which eliminates the need to go through all of our concordance lines manually. Because MorphoQuantics only reports the frequencies at the level of the entire spoken component of the BNC, however, we do need to disambiguate individual instances of words such as copper, which can denote both ‘metal’ and ‘police officer’, only the latter of which has been formed using the suffix -er. Furthermore, since we wish to differentiate between animate and inanimate senses of the suffixes (which MorphoQuantics does at the level of the entire corpus), we need to go through and annotate instances of words that can be either, such as cleaner (‘a person who cleans’ vs. ‘a substance that cleans’).
After annotating the data in this manner, we enter it into the types2 software along with the corpus metadata. We then use types2 to analyse productivity as described in Section 2.1 and to produce the web-based output for exploring the results. For more details, see types2: User’s Manual (Suomela & Säily 2016).
Results
The landing page of the web-based output of types2 immediately reveals the most significant results (Figure 3). In addition to type and hapax frequencies, we have chosen to calculate token frequencies (i.e. we count each occurrence of a word containing the suffix); these are shown in grey as they do not indicate productivity. The results are ordered by p-value, lowest first. We also show the false discovery rate (FDR) for each finding; results listed after the threshold of FDR ≈ 0.1 are probably not interesting, as at this point up to 10% of the findings are expected to be false positives.
We can immediately see that there is a gender difference in the productivity of -er. The most significant result is that women use inanimate -er (‘er-thing’) less productively than men (side ‘below’). They also use -er as a whole less productively than men, and further down the list we get the same result for animate -er (‘er-person’). None of the results for -or are significant after FDR control, perhaps because -or is relatively infrequent, so we do not have enough evidence to prove anything one way or the other. In addition, none of the significant results are based on hapax legomena, which is to be expected as hapax-based measures require more data than type-based ones.
Note that the type frequencies are calculated for two different measures of corpus size: the number of running words in the corpus (‘types / running words’) and the number of word tokens having the suffix in question (‘types / tokens’). Both of these measures may be of interest as they represent slightly different aspects of productivity. We can see that the female underuse (as well as male overuse) of inanimate -er is significant in terms of both measures, making the phenomenon quite robust.
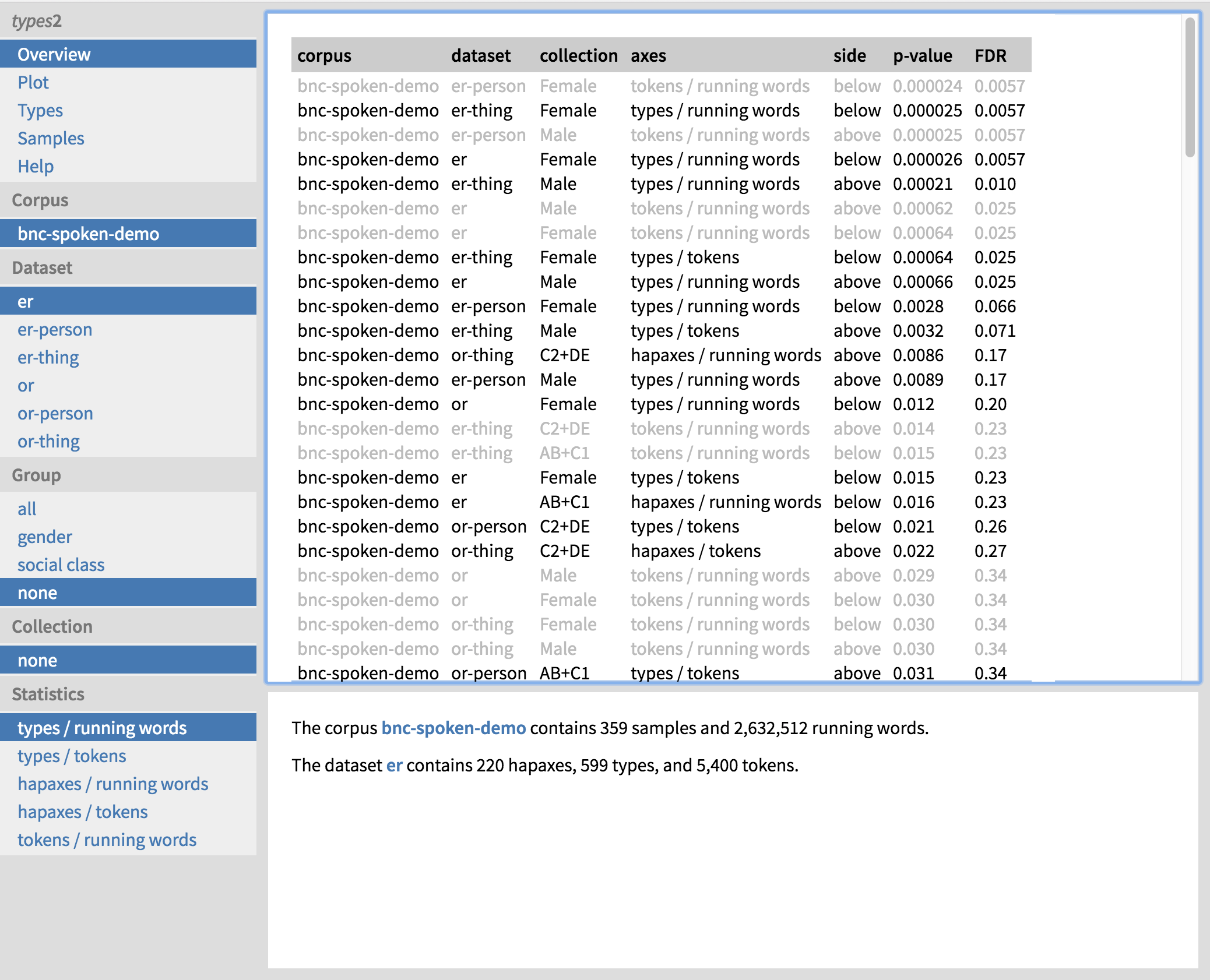
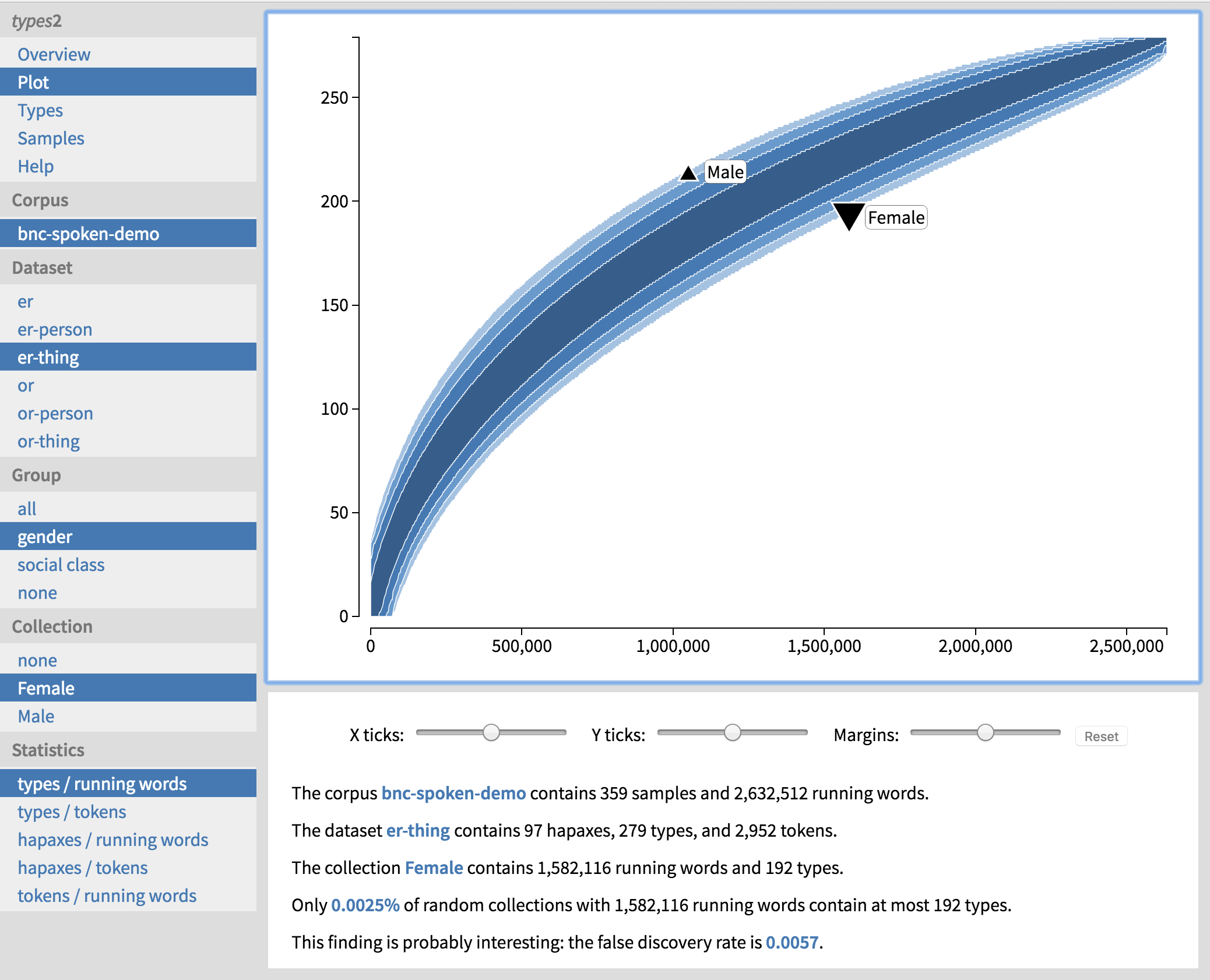
How can we interpret these results? Let us click on the first row of text in black, showing the female underuse of inanimate -er. More details on the female subcorpus and the dataset of inanimate -er appear at the bottom of the screen. We can also view this result in the form of a plot by clicking on ‘Plot’ on the top left (Figure 4). This banana-shaped plot shows confidence intervals for type frequencies at each possible subcorpus size, from zero to the size of the entire corpus. We can see that as the size of the corpus increases (x-axis), so does the number of types (y-axis), but in a non-linear manner. The female subcorpus is hanging from the bottom edge of the banana, which means that almost all of the randomly composed subcorpora of the same size have a higher type frequency than the female subcorpus. This is also expressed in words below the plot. We can explore the other results visually as well by selecting the appropriate dataset, social group and subcorpus (‘Collection’) in the navigation panel on the left.
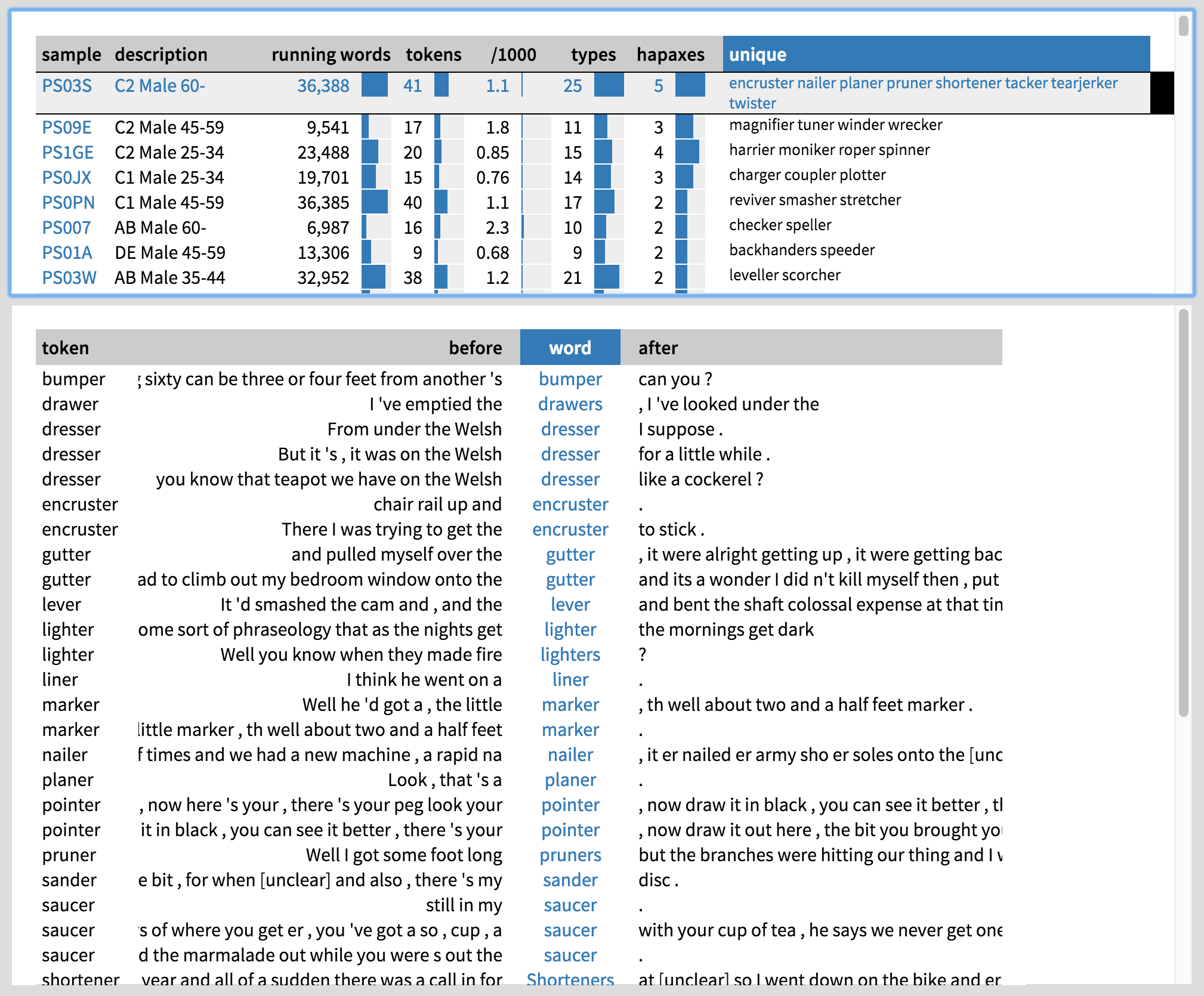
These plots do not tell the whole story, however. To interpret the results, we need to know how men and women are using -er, and what kind of people they are. Let us explore the inanimate -er types used by women by clicking on ‘Types’ on the top left. By default, the list of types is sorted by ‘score’, which roughly speaking shows those types first that are the most characteristic of women’s speech in the corpus. Rather depressingly stereotypically, we get household items like dryer and duster, items of clothing like bloomer and boxer, hair-care items like conditioner and curler, and so on. To explore how these words are used, we can click on them to view the concordance lines along with speaker metadata at the bottom of the screen (Figure 5; you can press ‘z’ in the tool to make the concordance panel bigger). If we need even more context, we can click on each keyword to view the entire conversation in BNCweb, and for more information on the speaker, we can click on the speaker ID under ‘sample’.
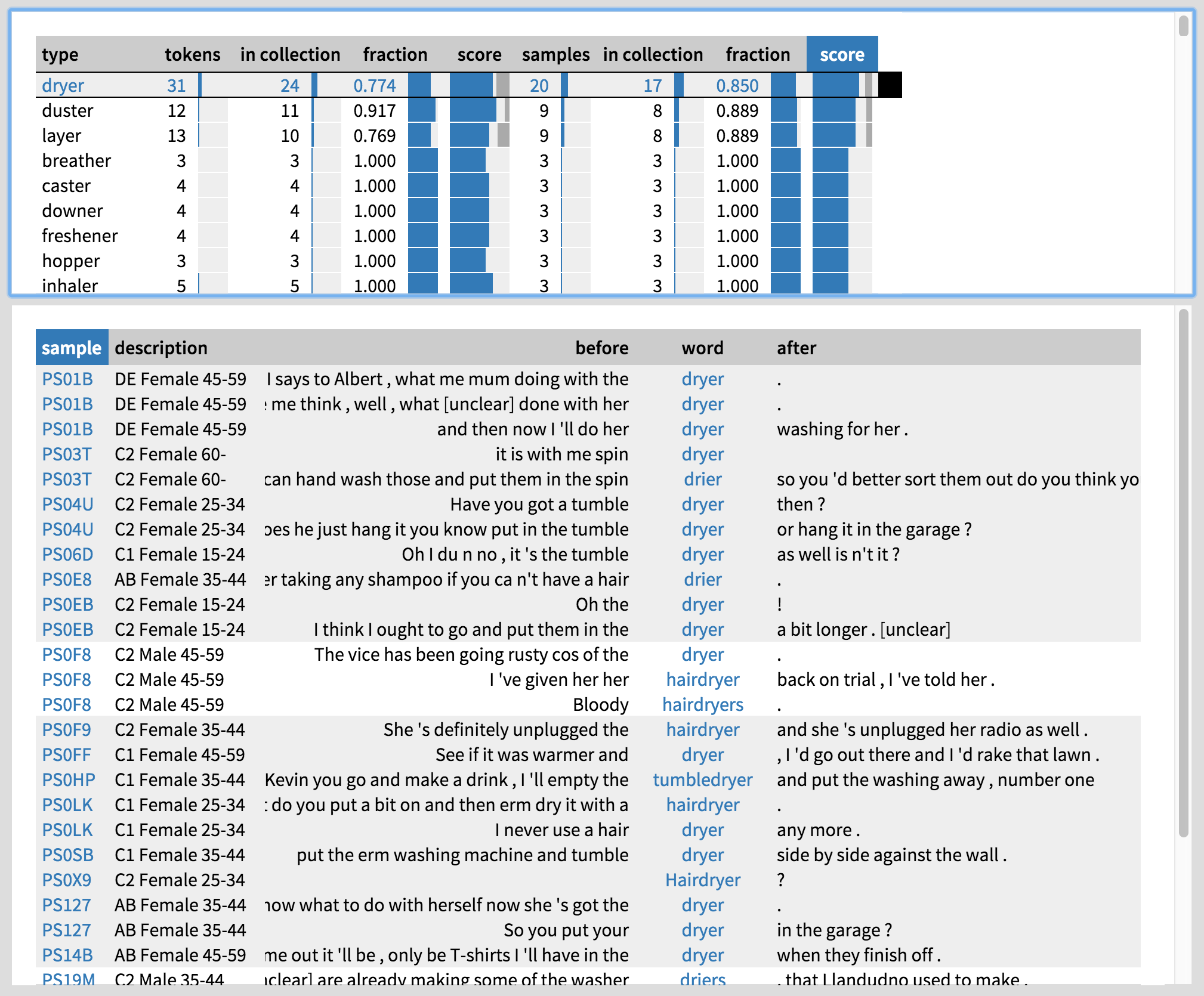
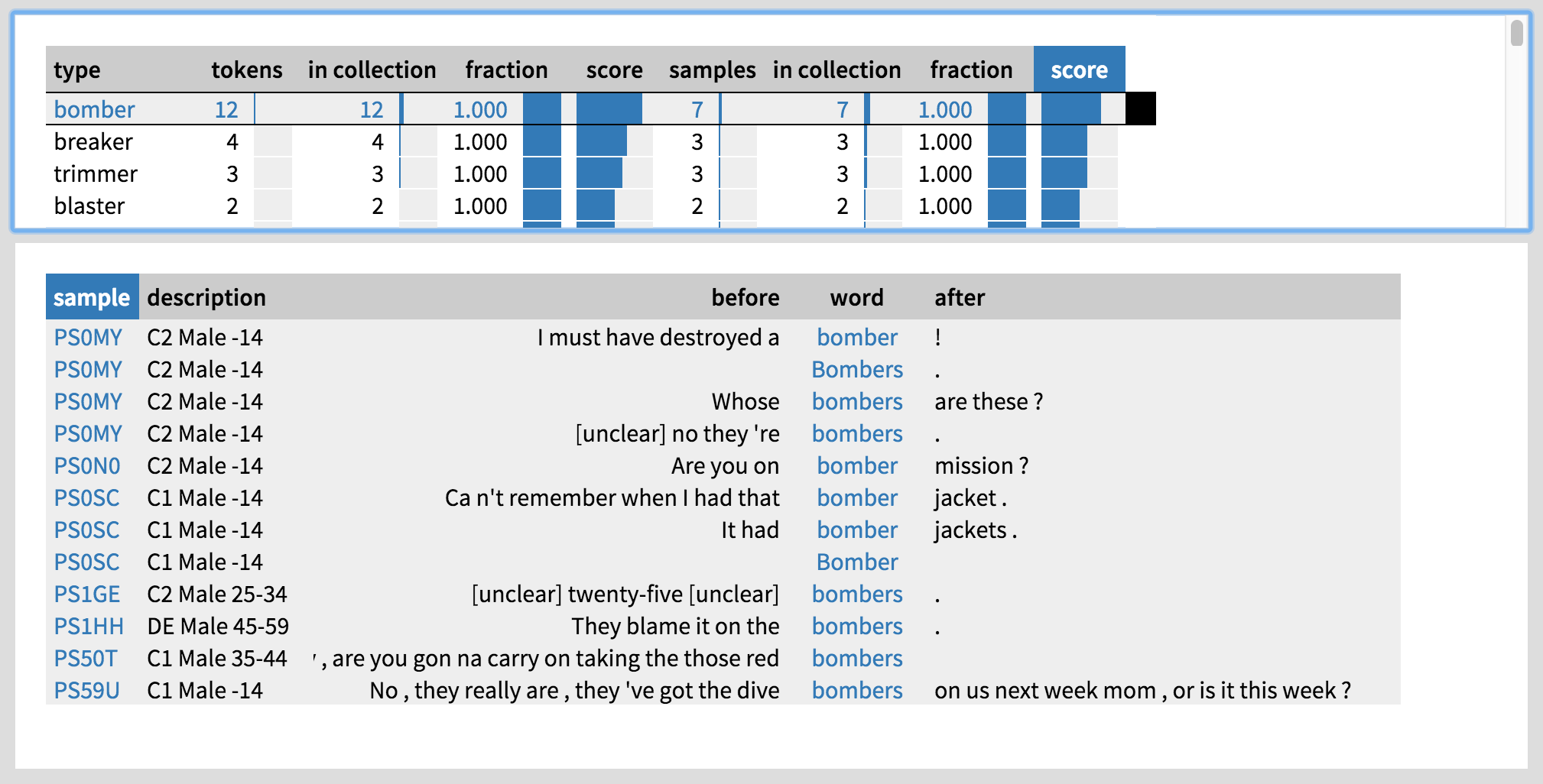
What about the men? To find out, let us click on the ‘Male’ collection on the left. We get masculine-sounding items like bomber, blaster, booster, technical ones like decoder and equaliser, more common tools like trimmer and carver… Clicking on bomber (Figure 6), we see that many of the speakers are in fact boys under 15 years of age, which would suggest that they may be playing a computer game. This immediately brings to mind two hypotheses: both age and setting may be important factors. Some of the more technical terms may have been uttered at work, which indeed seems to be the case when looking at the setting information in BNCweb. Moreover, many of the -er words used by women seem to be home-related, so setting is definitely a factor worth investigating.
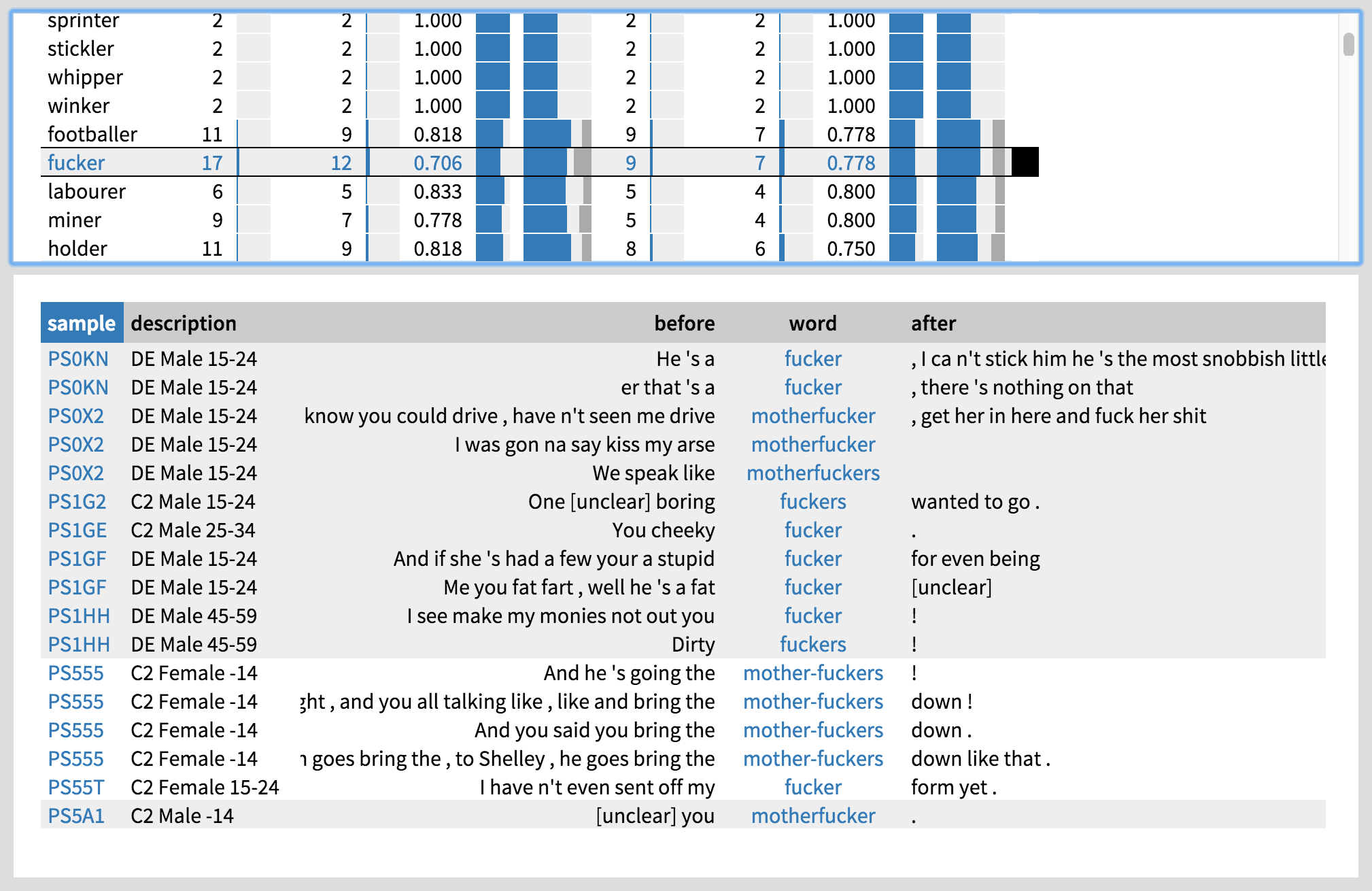
Let us next examine the animate -er words used by men by selecting the ‘er-person’ dataset on the left. There are quite a few professions like carpenter and banker. Some interesting insults also pop up: blighter, loser, plonker, further down the list also e.g. fucker, geezer and wanker. Let us take a closer look at fucker (Figure 7). Even though there are a couple of young female users of fucker (their concordance lines are marked with white), the bulk of the users seem to be young working-class men (C2 and DE roughly correspond to working class in the BNC metadata coding). Thus, in addition to gender, age and social class may be relevant social factors in the productivity of animate -er; even though social class did not emerge as significant on its own, perhaps it is the combination of gender and social class that matters.
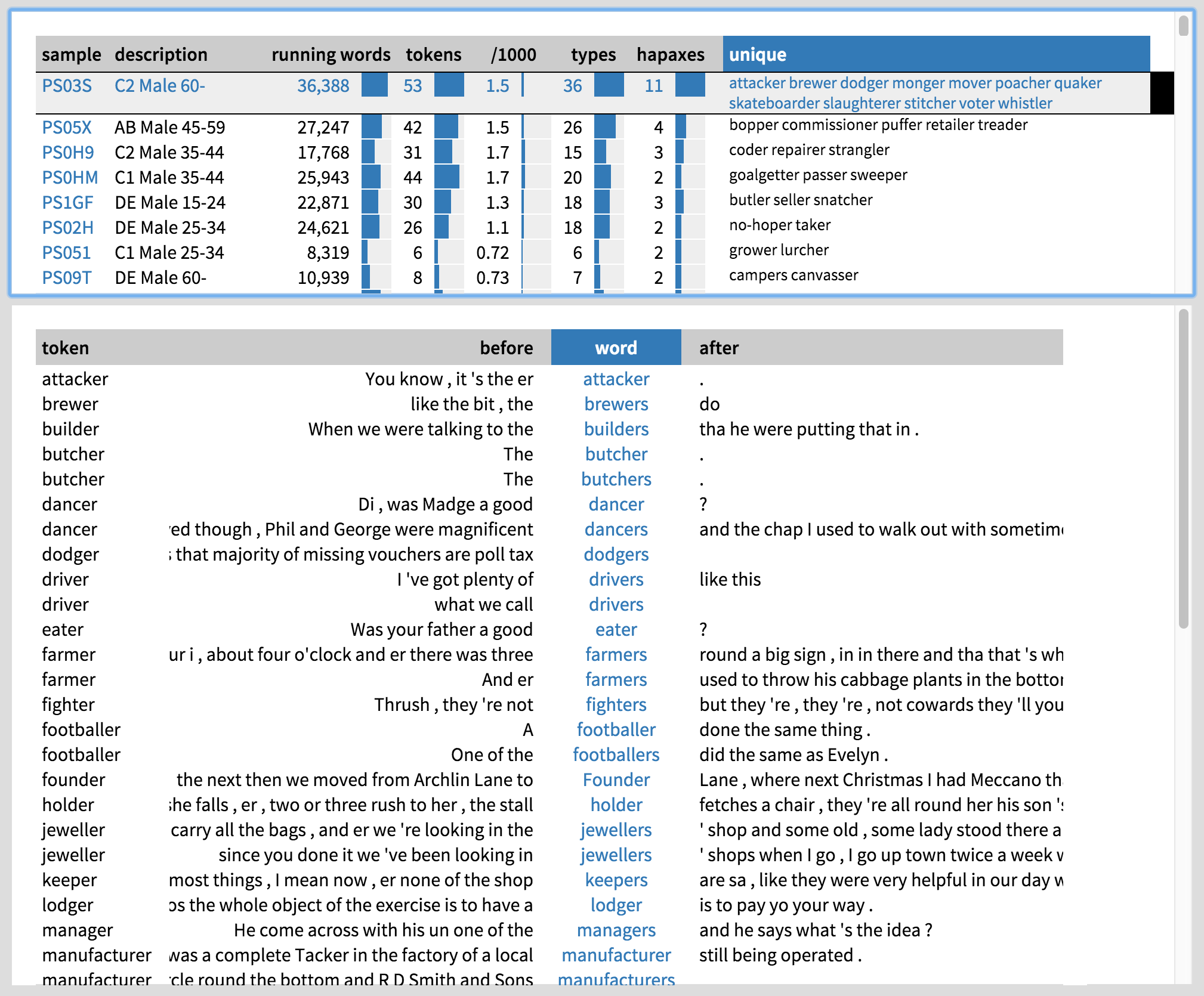
Finally, let us zoom in on the individual men who use animate -er by clicking on ‘Samples’ on the top left. By default, they are sorted by the number of running words they have uttered, which does not tell us much about the extent to which they use -er. Let us sort them by the unique animate -er words they use. By this measure, the top user of -er is a working-class man who is over 60 years of age. We can click on his row to see the concordance lines of his -er instances (Figure 8). We can also click on the name of the sample to view the speaker information in BNCweb (Figure 9). As it turns out, this speaker is 82 and a retired precision engineer. He also seems to use inanimate -er with a considerable frequency (Figure 10); perhaps engineers, who use all sorts of technical gadgets in their work, are more likely to use -er in general?
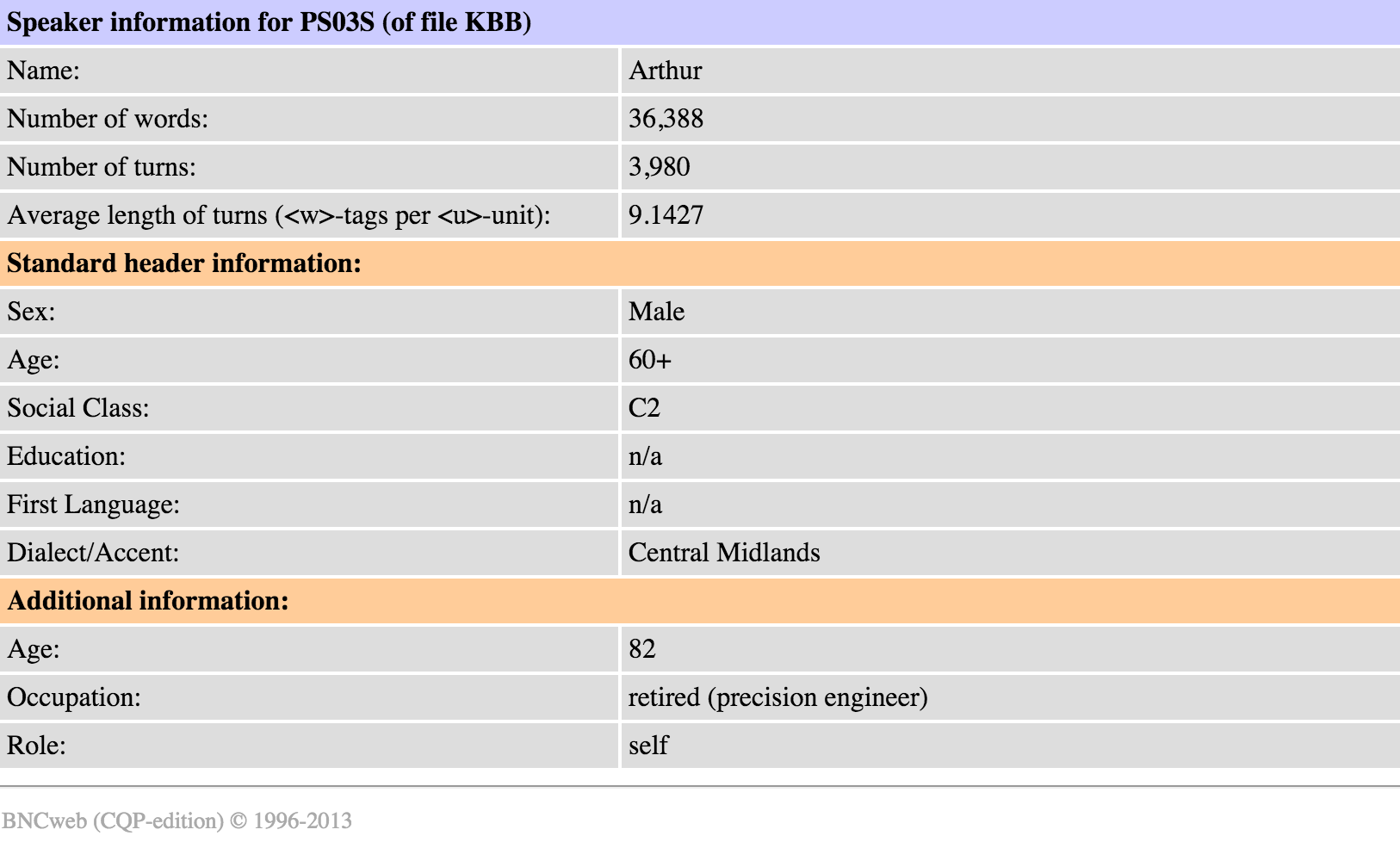
Based on our exploration, we may advance some tentative explanations for the male overuse of -er. Firstly, men seem to focus more on tools and occupations than women. This might be linked to the factor of setting: if more of the male conversations have been recorded at work, it would be natural for them to talk more about the tools and occupations relevant there. Secondly, men’s use of animate -er clearly has a component of playful name-calling. This may be influenced by factors like age and social class, perhaps also setting and the relationship between the interlocutors (friends at a pub are more likely to engage in banter and playful insults than an employer and employee at work).
We wish to emphasize that this is only the starting point for a complete analysis. With the help of types2, we have generated new hypotheses regarding possibly relevant social factors, such as age and setting. The next step would be to test the influence of these, possibly in combination with others. We will report our results, some of which have been presented in Säily et al. (2016), in a future publication.
Case study: CEEC, -ity, and -ness
Our second example briefly explores sociolinguistic variation and change in the productivity of the nominal suffixes -ness and -ity in 18th-century English correspondence (Säily 2016, forthcoming). These suffixes are typically used to derive abstract nouns from adjectives (e.g. productive : productiveness, productivity). While -ness is a native suffix, -ity was borrowed from French and Latin and can be seen as the more prestigious, formal and learned alternative. As such, -ity is expected to be more susceptible to variation and change (see further Säily 2014).
Data and procedure
Our material comes from the 18th-century section of the Corpora of Early English Correspondence (CEEC), which consists of 4,945 letters written by 315 people, or a total of c. 2.2 million words. The time period covered is 1680–1800, or the ‘long eighteenth century’, which begins with the English Restoration. This period also has the advantage that it can be easily subdivided into 20- and 40-year periods, which are commonly used in sociolinguistic research as 20 years roughly corresponds to one generation. We search the corpus using WordSmith Tools (Scott 2016) and prune the search results down to relevant hits only in Excel. We then use the types2 software to analyse productivity as in the previous case study (Section 2).
Results
Looking at the types2 landing page, a number of interesting results present themselves (Figure 11). Most importantly, the productivity of -ity is significantly low in the first subperiod, regardless of the measure of corpus size and periodization we use (20-year periods are represented by the starting year only, e.g. ‘1680’, while 40-year periods are shown in their entirety, e.g. ‘1680–1719’). We can also see that the the productivity of -ity is significantly high in the last 40-year period, 1760–1800. All this suggests that the productivity of -ity increases over time.
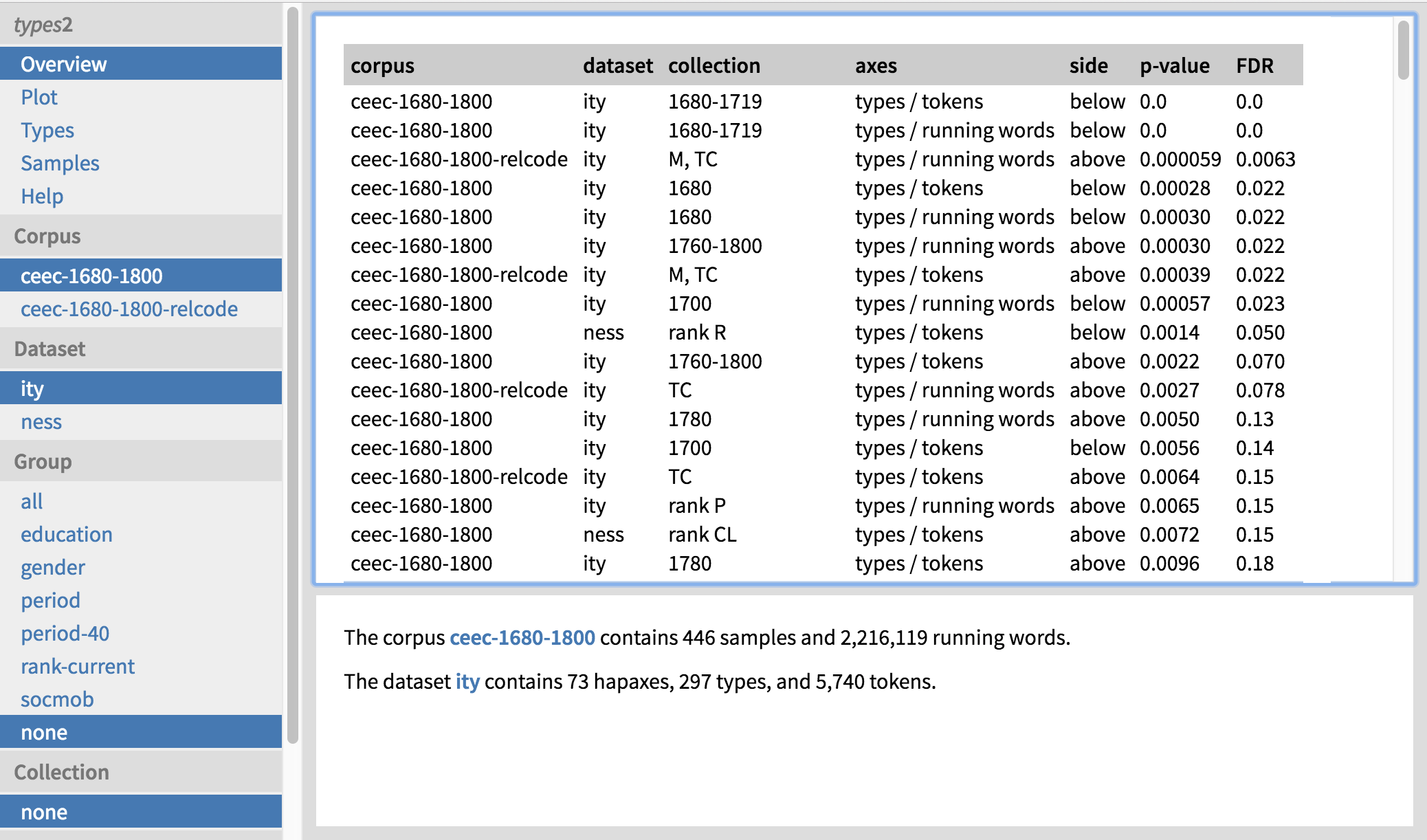
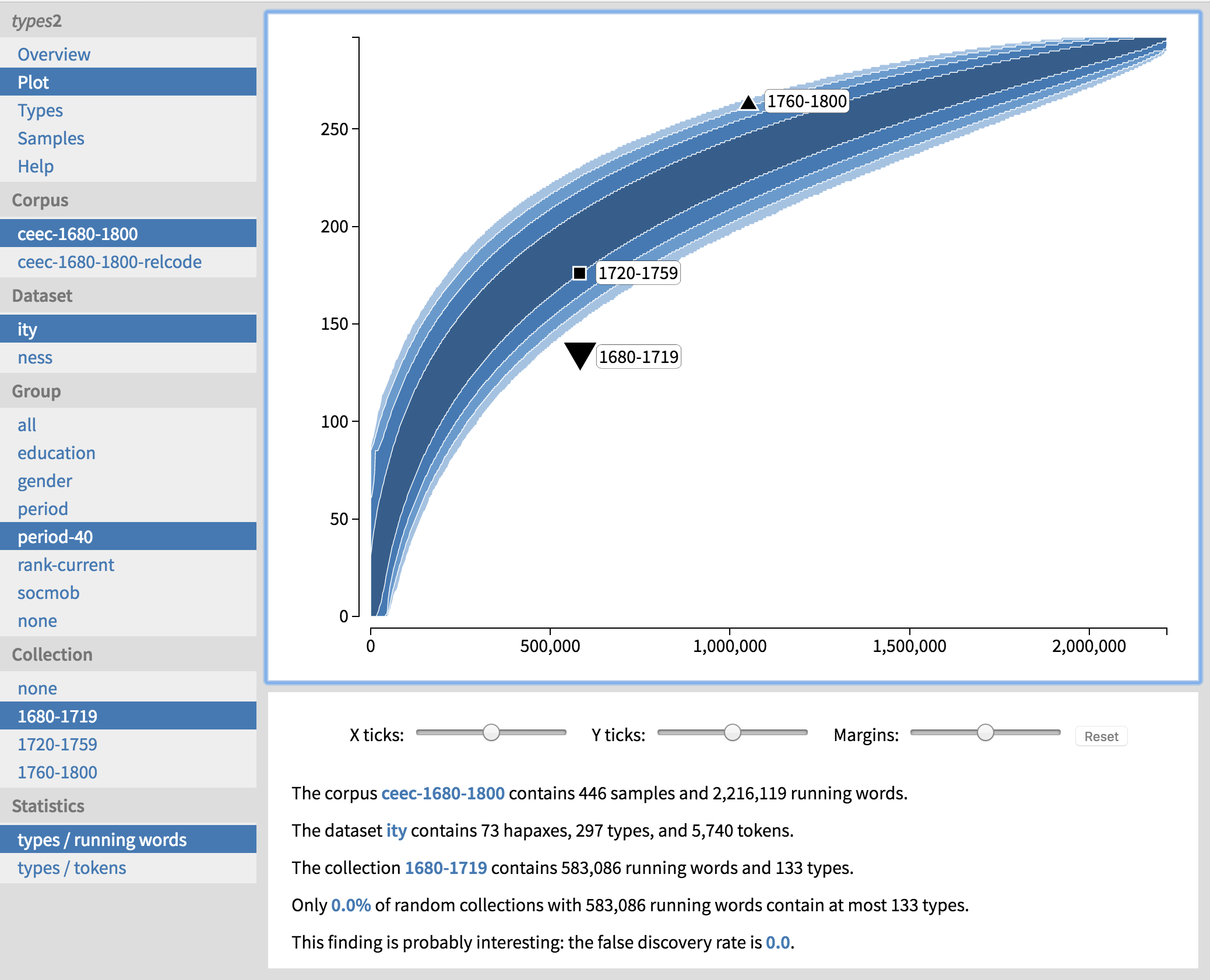
This result becomes even clearer when we inspect one of the plots by clicking on the second result followed by ‘Plot’ on the top left (Figure 12). The first period hangs way below the banana representing what is normal in the corpus as a whole, the middle period is not significantly different from the corpus as a whole, and the last period is at the top edge, so that the bulk of the corpus is below it.
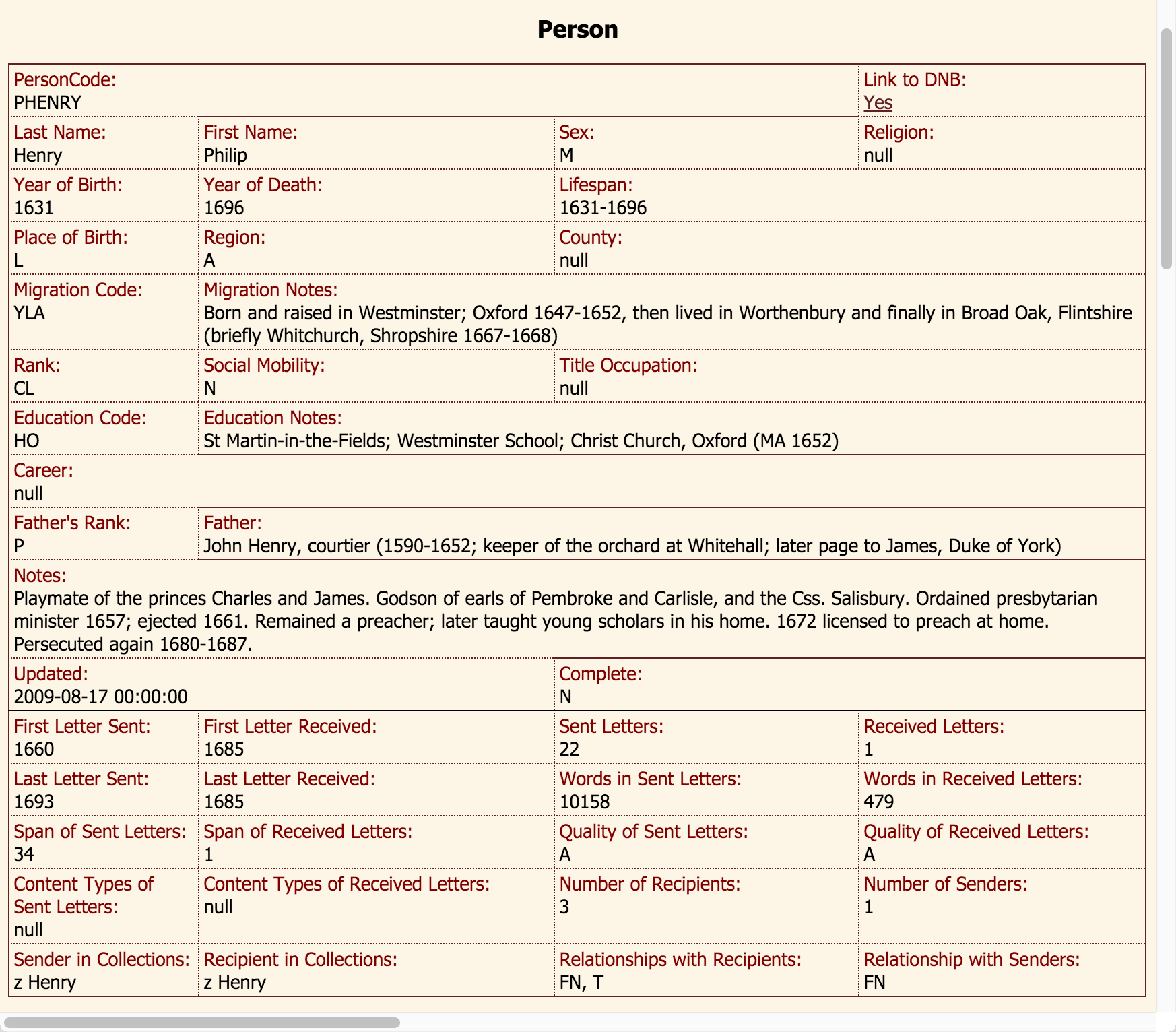
How can we interpret this change? Let us have a look at the -ity types used in the first 40-year period by clicking on ‘Types’ on the top left. They appear to be quite complex entities: we have possibly religion-related words like (non)conformity and fallibility, items related to law and commerce such as immunity and commodity, and words with negative connotations such as infelicity and extremity. Taking nonconformity under closer inspection, we can see that the two instances were produced by D. Defoe and P. Henry (Figure 13). Registered users of CEECer, an in-house tool for exploring CEEC data and metadata, can click on the keywords to view the entire letters, or on the names of the samples to view more information on these people. The letter-writers are in fact the author Daniel Defoe and clergyman Philip Henry (Figure 14), who were both Protestant dissenters, so this word reflects the society of the time.
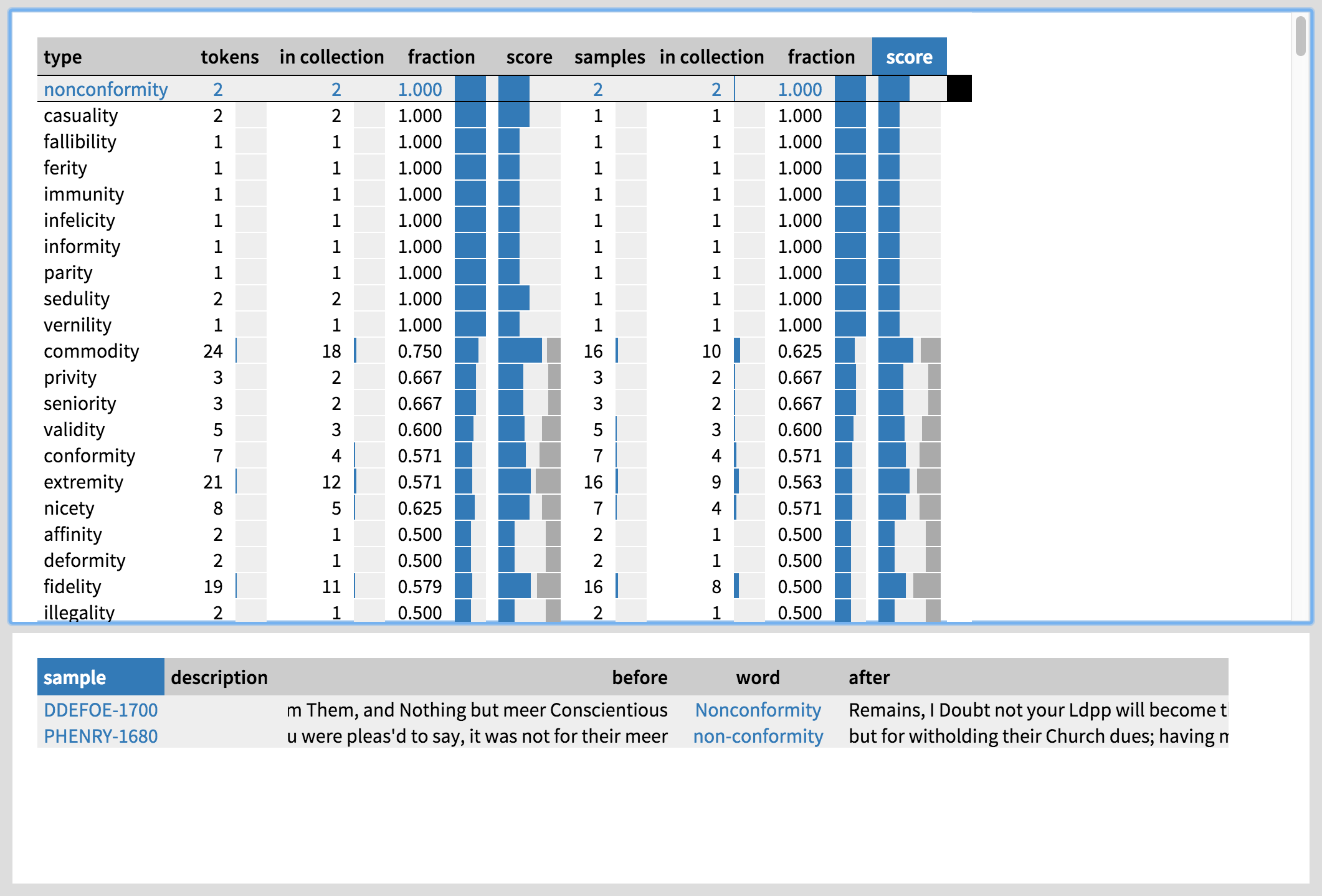
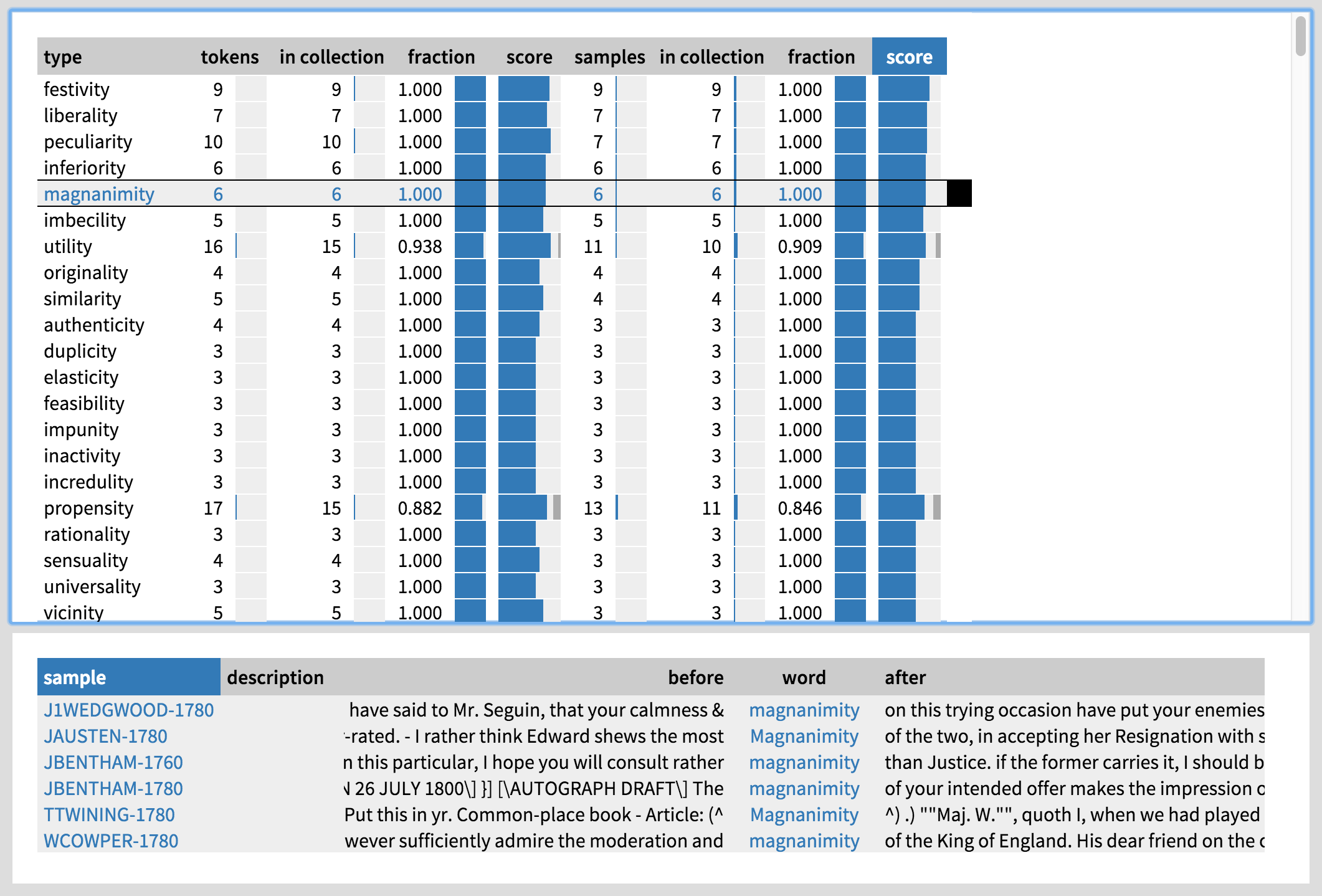
Next, let us explore the -ity types used in the last period by clicking on the collection ‘1760–1800’ on the left. Quite a different picture emerges: there seem to be a large number of words describing attributes or traits, such as liberality, peculiarity, inferiority, and magnanimity, which are not domain-specific and which have both positive and negative connotations. After clicking on magnanimity (Figure 15), we can see that quite a few of the instances refer to people: your calmness & magnanimity
, Edward shews the most Magnanimity
, etc. The writers include Josiah Wedgwood (master potter), Jane Austen (author), Jeremy Bentham (philosopher), Thomas Twining (clergyman), and William Cowper (poet), i.e., mostly professionals.
To sum up, the semantics of -ity seems to change over time as well as its productivity. This may be related to a change in the letter-writing genre in Late Modern England towards a more involved and elaborated style (Biber & Finegan 1997). Furthermore, as noted by Säily (forthcoming), the functions of letter-writing may have changed: at least for the upper classes, letter-writing may have become “more about maintaining and building social relationships and identities than about conveying information”. The use of the prestigious and stylistically elevated -ity to describe people’s attributes would fit in well with these changes. Our limited exploration would also seem to indicate that the change could have been led by the professional class; this is supported by a more extensive study in Säily (forthcoming).
Conclusions
We have seen that linked data as employed by the types2 tool facilitates research in two ways. Firstly, it helps with generating new hypotheses: in the case of -er, we hypothesized that age, setting and relationship might be significant in addition to gender and social class, so these factors could be added to the analysis. Secondly, interactive exploration helps with interpreting results. We have tentatively been able to connect the male overuse of -er with a focus on tools and occupations as well as with playful name-calling, which may be part of masculine identity-building in late twentieth-century Great Britain. In the case of -ity, we have discovered a link between increased productivity and semantic change, which may be related to changes in the style and functions of letter-writing in Late Modern England.
We believe that types2 significantly facilitates making sense of rich data in a way that few other current tools can (cf. Anthony 2013). While corpus tools like AntConc and WordSmith Tools are excellent for standard corpus-linguistic research, they offer little support for the close integration of data and metadata. BNCweb and its more general cousin, CQPweb (Hardie 2012), do support metadata to an extent, but not in the fluid and exploratory way enabled by types2. But then these tools complement each other: as our tool was not designed for concordancing, it needs to be used in combination with the above-mentioned software. types2 is open-access and works with multiple corpora and concordancers. While the web interface is easy for any linguist to use, entering data into types2 and running the analysis requires some computational expertise (see the User’s Manual), so collaboration with a more technically minded colleague may be a good idea for these stages. Feel free to contact us for help as well.
Future improvements to the tool may include a measure of effect size in addition to statistical significance (Gries 2005) and a more direct support for multivariate analysis. Another useful feature could be to go beyond exploration and enable further analysis of the different groups of types within the tool. For instance, the animate -er types could be grouped into insults vs. other within the web interface, after which the statistical analysis could be run for these two groups separately. A third possible improvement would be to use even more linked data, e.g. to link all types to their entries in the Oxford English Dictionary and the Historical Thesaurus, or to automatically retrieve data from these resources to be displayed alongside the types. Moreover, in historical sociolinguistic research we need background information from social history, so the different time periods could be linked to online resources describing them. We welcome any feature suggestions from the community.
Acknowledgements
The authors wish to thank CSC – IT Center for Science, Finland, for computational resources. We would also like to thank the participants at the d2e conference for comments on an earlier version of this paper, and the anonymous reviewers for their helpful feedback. This work was supported in part by the Academy of Finland grant 276349 to the project ‘Reassessing language change: the challenge of real time’.
Data cited herein have been extracted from the British National Corpus, distributed by the University of Oxford on behalf of the BNC Consortium. All rights in the texts cited are reserved.
References
Anthony, Laurence. 2013. A critical look at software tools in corpus linguistics. Linguistic Research 30(2): 141–161. doi:10.17250/khisli.30.2.201308.001
Baayen, R. H. 2009. Corpus linguistics in morphology: morphological productivity. In Anke Lüdeling & Merja Kytö (eds.), Corpus linguistics: an international handbook, 899–919. Berlin: Mouton de Gruyter. doi:10.1515/9783110213881.2.899
Bauer, Laurie. 2001. Morphological productivity (Cambridge Studies in Linguistics 95). Cambridge: Cambridge University Press.
Bauer, Laurie, Rochelle Lieber & Ingo Plag. 2013. The Oxford reference guide to English morphology. Oxford: Oxford University Press.
Benjamini, Yoav & Yosef Hochberg. 1995. Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society. Series B (Methodological) 57(1): 289–300. http://www.jstor.org/stable/10.2307/2346101
Bestgen, Yves. 2014. Inadequacy of the chi-squared test to examine vocabulary differences between corpora. Literary and Linguistic Computing 29(2): 164–170. doi:10.1093/llc/fqt020
Biber, Douglas & Edward Finegan. 1997. Diachronic relations among speech-based and written registers in English. In Terttu Nevalainen & Leena Kahlas-Tarkka (eds.), To explain the present: studies in the changing English language in honour of Matti Rissanen (Mémoires de la Société Néophilologique de Helsinki 52), 253–275. Helsinki: Société Néophilologique.
BNC = The British National Corpus, version 3 (BNC XML edition). 2007. Distributed by Oxford University Computing Services on behalf of the BNC Consortium. http://www.natcorp.ox.ac.uk
Bolinger, Dwight L. 1948. On defining the morpheme. Word 4: 18–23. doi:10.1080/00437956.1948.11659323
Brezina, Vaclav & Miriam Meyerhoff. 2014. Significant or random? A critical review of sociolinguistic generalisations based on large corpora. International Journal of Corpus Linguistics 19(1): 1–28. doi:10.1075/ijcl.19.1.01bre
CEEC = Corpora of Early English Correspondence. Compiled by Terttu Nevalainen, Helena Raumolin-Brunberg et al. at the Department of Modern Languages, University of Helsinki. https://varieng.helsinki.fi/CoRD/corpora/CEEC/
Cowie, Claire & Christiane Dalton-Puffer. 2002. Diachronic word-formation and studying changes in productivity over time: theoretical and methodological considerations. In Javier E. Díaz Vera (ed.), A changing world of words: studies in English historical lexicography, lexicology and semantics (Costerus New Series 141), 410–437. Amsterdam: Rodopi.
Dwass, Meyer. 1957. Modified randomization tests for nonparametric hypotheses. The Annals of Mathematical Statistics 28(1): 181–187. http://projecteuclid.org/euclid.aoms/1177707045
Gries, Stefan Th. 2005. Null-hypothesis significance testing of word frequencies: a follow-up on Kilgarriff. Corpus Linguistics and Linguistic Theory 1(2): 277–294. doi:10.1515/cllt.2005.1.2.277
Hardie, Andrew. 2012. CQPweb – combining power, flexibility and usability in a corpus analysis tool. International Journal of Corpus Linguistics 17(3): 380–409. doi:10.1075/ijcl.17.3.04har
Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee & Ylva Berglund Prytz. 2008. Corpus linguistics with BNCweb – a practical guide (English Corpus Linguistics 6). Frankfurt am Main: Peter Lang.
Kilgarriff, Adam. 2005. Language is never, ever, ever, random. Corpus Linguistics and Linguistic Theory 1(2): 263–275. doi:10.1515/cllt.2005.1.2.263
Laws, Jacqueline & Chris Ryder. 2014a. MorphoQuantics. http://morphoquantics.co.uk
Laws, Jacqueline & Chris Ryder. 2014b. Getting the measure of derivational morphology in adult speech: a corpus analysis using MorphoQuantics. Language Studies Working Papers: University of Reading, Vol. 6, 3–17. http://morphoquantics.co.uk/Resources/Laws%20&%20Ryder%20(2014).pdf
Lijffijt, Jefrey, Terttu Nevalainen, Tanja Säily, Panagiotis Papapetrou, Kai Puolamäki & Heikki Mannila. 2016. Significance testing of word frequencies in corpora. Digital Scholarship in the Humanities 31(2): 374–397. doi:10.1093/llc/fqu064
Lijffijt, Jefrey, Tanja Säily & Terttu Nevalainen. 2012. CEECing the baseline: lexical stability and significant change in a historical corpus. In Jukka Tyrkkö, Matti Kilpiö, Terttu Nevalainen & Matti Rissanen (eds.), Outposts of historical corpus linguistics: from the Helsinki Corpus to a proliferation of resources (Studies in Variation, Contacts and Change in English 10). Helsinki: VARIENG. https://varieng.helsinki.fi/series/volumes/10/lijffijt_saily_nevalainen/
Pike, William A., John T. Stasko, Remco Chang & Theresa A. O’Connell. 2009. The science of interaction. Information Visualization 8(4): 263–274. doi:10.1057/ivs.2009.22
Plag, Ingo. 1999. Morphological productivity: structural constraints in English derivation (Topics in English Linguistics 28). Berlin: Mouton de Gruyter.
Plag, Ingo. 2003. Word-formation in English (Cambridge Textbooks in Linguistics). Cambridge: Cambridge University Press. doi:10.1017/CBO9780511841323
Säily, Tanja. 2008. Productivity of the suffixes -ness and -ity in 17th-century English letters: a sociolinguistic approach. Unpublished MA thesis, Department of English, University of Helsinki. http://urn.fi/URN:NBN:fi-fe200810081995
Säily, Tanja. 2011. Variation in morphological productivity in the BNC: sociolinguistic and methodological considerations. Corpus Linguistics and Linguistic Theory 7(1): 119–141. doi:10.1515/cllt.2011.006
Säily, Tanja. 2014. Sociolinguistic variation in English derivational productivity: studies and methods in diachronic corpus linguistics (Mémoires de la Société Néophilologique de Helsinki 94). Helsinki: Société Néophilologique. http://urn.fi/URN:ISBN:978-951-9040-50-9
Säily, Tanja. 2016. Sociolinguistic variation in morphological productivity in eighteenth-century English. Corpus Linguistics and Linguistic Theory 12(1): 129–151. doi:10.1515/cllt-2015-0064
Säily, Tanja. Forthcoming. Change or variation? Productivity of the suffixes -ness and -ity. In Terttu Nevalainen, Minna Palander-Collin & Tanja Säily (eds.), Sociolinguistic change in 18th-century English.
Säily, Tanja & Jukka Suomela. 2009. Comparing type counts: the case of women, men and -ity in early English letters. In Antoinette Renouf & Andrew Kehoe (eds.), Corpus linguistics: refinements and reassessments (Language and Computers: Studies in Practical Linguistics 69), 87–109. Amsterdam: Rodopi. https://jukkasuomela.fi/comparing-type-counts/
Säily, Tanja, Jukka Suomela & Eetu Mäkelä. 2016. Variation in morphological productivity in the history of English: the case of -er. Presentation, International Society for the Linguistics of English (ISLE 4), Poznań, Poland, September 2016. https://tuhat.halvi.helsinki.fi/portal/files/69118357/isle4_ts_js_em.pdf
Scott, Mike. 2016. WordSmith Tools. Computer program. Stroud: Lexical Analysis Software. http://www.lexically.net/wordsmith/
Suomela, Jukka. 2016. types2: type and hapax accumulation curves. Computer program. https://jukkasuomela.fi/types2/
Suomela, Jukka & Tanja Säily. 2016. types2: User’s Manual. https://jukkasuomela.fi/types2-manual/