types2: User’s Manual
5 October 2016
Introduction
types2 is a freely available corpus tool for comparing the frequencies of words, types, and hapax legomena across subcorpora. The tool uses accumulation curves and the statistical technique of permutation testing to compare the subcorpora with a “typical” corpus of a similar size, in order to visualize the frequencies and to identify statistically significant findings. The new version of the tool makes it easy to explore the results with the help of an interactive web user interface that provides direct access to relevant findings, visualizations, metadata, and corpus texts (Figure 1).
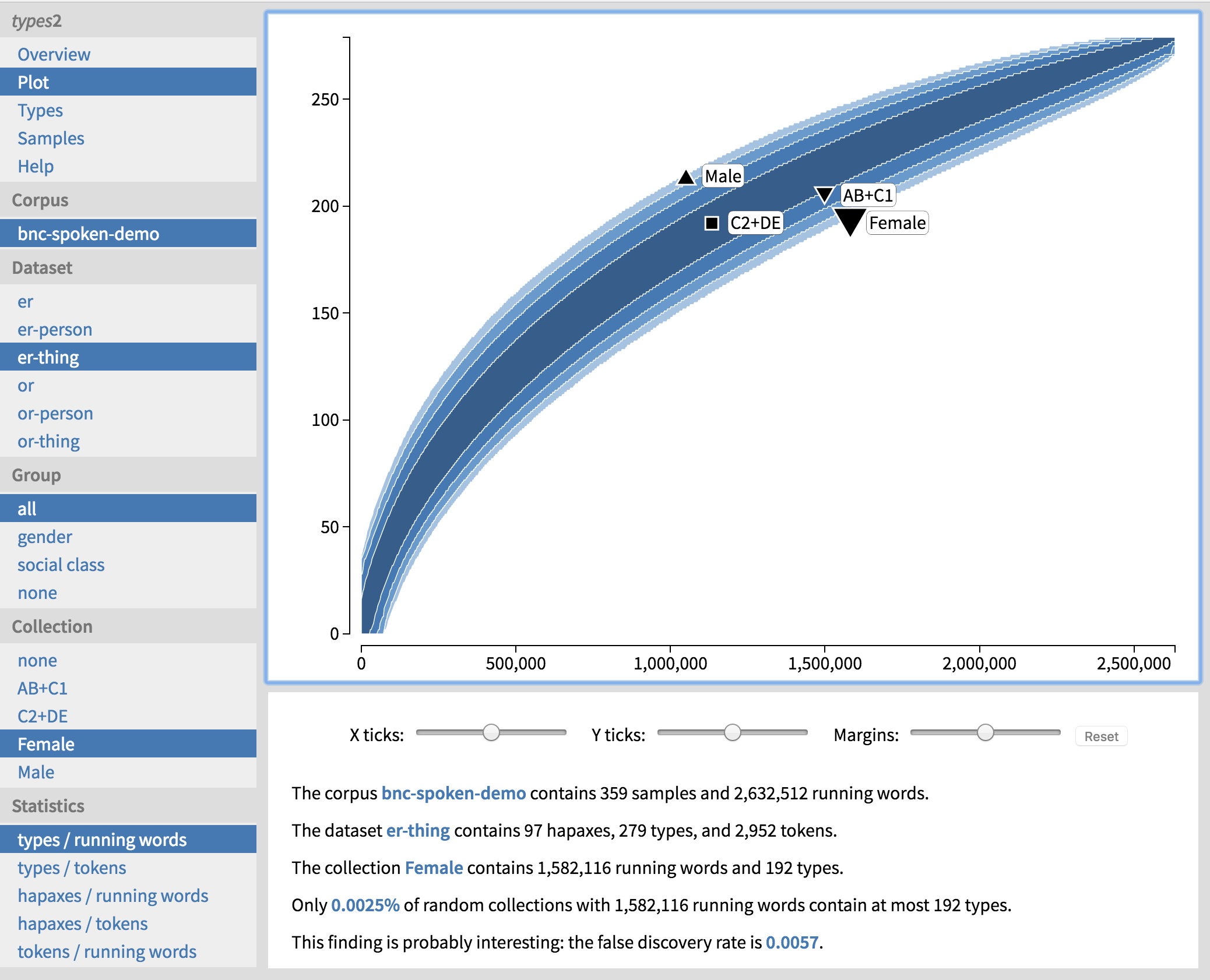
The basic principles of the tool, as well as how to use it to explore and analyse corpus data, are explained in the paper “types2: Exploring word-frequency differences in corpora” (Säily & Suomela 2016). In this manual we will look at the more technical part: given your data, how to enter it in types2, run the data analysis, and start to explore the results.
In this manual, we will use the same running examples and data sets as in the above paper:
- The nominal suffix -er in the demographically sampled spoken component of the British National Corpus (BNC).
- The nominal suffixes -ness and -ity in the Corpora of Early English Correspondence (CEEC).
Backend and frontend
The results that you see in the web user interface (see Figure 1 for an example) are precomputed. Permutation testing is computationally intensive, and we do not want to redo it in the web browser every time we start to explore the results.
Our tool consists of two separate parts, which we will refer to as the backend and the frontend. The frontend is the web interface that we have already seen; the backend is the set of tools that performs the heavy computations. The backend and the frontend are of a fairly different nature, as summarized in the following table.
| Backend | Frontend | |
|---|---|---|
| User interface | command-line tools that you run in terminal | web pages that you access with a web browser |
| Supported platforms | OS X and Linux | modern web browsers |
| Programming languages | C and Python | JavaScript |
| APIs, standards, libraries, and external resources | OpenMP, SFMT, SFMTJump (Saito & Matsumoto 2008) |
HTML5, SVG, D3.js, Source Sans Pro, Google Fonts |
| Data storage | SQLite database, read-write | JSON-formatted text file, read-only |
| Running time | may take several minutes | instantaneous |
For any given data set and research question, you only need to run the backend once. After that, you will have all your results in one folder, together with the web user interface, and you can easily distribute it among your colleagues and even make it available online – just like we have done with our sample data set.
Database
From the user’s perspective, the key component of the backend is the SQLite database that is used to store information. An SQLite database is just a single file. In our case the file is usually named db/types.sqlite
. This is the database in which you will enter all of the input data for the backend to process, and this is also the database that will eventually contain the end results of the analysis.
SQLite databases are very widely supported. Numerous programming languages support accessing SQLite databases; for example, in Python scripts you can use the standard module sqlite3
to read and write data in SQLite databases. On OS X and Linux you can use the command line tool sqlite3
to access the database. There are also graphical user interfaces for exploring SQLite databases and for importing and exporting data; one option for OS X users is Base.app.
Software
Our tool is freely available for download at the following sites:
- Github: github.com/suomela/types
- Bitbucket: bitbucket.org/suomela/types
The software distribution comes with up-to-date installation instructions. In brief, you will need a Unix-like operating system (e.g., OS X or Linux), a modern C compiler, Python 2, and SQLite development libraries. After downloading the software, you can configure it with the command ./config
, and compile it by running make
. Now you should have the backend of types2 ready for use in the bin
subdirectory.
Workflow
A typical workflow consists of the following steps:
- Create an empty database at
db/types.sqlite
. - Populate the database with your input data.
- Run
bin/types-run
to perform data analysis. - Run
bin/types-web
to create the web user interface.
After these steps, you should have a new subdirectory web
, which will contain the frontend of types2, together with the end results of the data analysis, ready for use. You can simply point your web browser to web/index.html
to explore the results. You do not need the database any more at this point, but naturally you should keep it in safe place in case you need to e.g. fix mistakes in the input and re-run the backend.
Typically, the most challenging part in the use of the tool is gathering your input data and getting it in the right format so that you can enter it in the database. To that end, we will need to understand the basic principles of how types2 works.
Basic principles
The key concept that one needs to understand is a sample. This is the smallest independent chunk of your corpus. The only modelling assumption that our software makes is that the samples are independent of each other. All data analysis is done at the level of samples. A typical choice in a sociolinguistic study would be:
- sample A = all texts written by author A.
Your corpus consists of all samples. You can then form any number of collections that consist of the samples that are of particular interest. In a sociolinguistic study, collections would typically reflect the social metadata associated with your samples, for example:
- collection X = all texts written by authors of social class X,
- collection Y = all texts written by authors of gender Y.
In essence, types2 will form a very large number of random collections and compare them with the collections that you have specified in the database. In the CEEC example, we can then see if, say, the number of -ness types in the collection of letters written by women is low or high in comparison with random collections of the same size. The null hypothesis here would be that type richness in the collection of letters written by women is no different from the type richness of a random collection.
For such an analysis to make sense, it is essential that the samples are indeed (relatively) independent of each other. In particular, the samples must not be too small. For example, one-sentence samples would typically be far too small, as individual sentences within the same text are not independent of each other. In the CEEC example, should we split our entire corpus in sentence-sized samples, we would get meaningless results. In brief, the issue would be that the random collections would be formed by freely mixing together individual sentences from different letters and by different authors, while the collections prepared by us would always keep each letter intact. Hence it would be only expected that the random collections would be more diverse.
We suggest the following rule of thumb for splitting your corpus in samples: if you randomly shuffle the order of the samples in your corpus, the end result would still make sense to a human reader. Naturally, this is not always easy to achieve, and e.g. in our BNC study we had to use a bit more creative approach.
The final concept that we will need is a token. A token is a single occurrence of a word of interest in the corpus. For example, in the CEEC study, each word formed with the suffix -ness is a token. For each token, we need to define a tokencode, which is a normalized form of the word. All occurrences with the same tokencode count as one type. A typical choice would be:
- tokencode = a normalized, lemmatized form of the word.
For example, in the CEEC study, we have normalized the spelling and lemmatized the words so that all spellings of e.g. the noun “witness”, in singular or plural, count as the same token. In that case, tokencode is simply the lemma.
Populating the database
Now we are ready to describe how to enter your data in the SQLite database used by types2. As a starting point, you can use the empty database that you will find in template/types.sqlite
: you can simply copy the template to db/types.sqlite
and start to fill it in.
The database structure is flexible enough that we can analyse multiple linguistic features at one go (for example, the diversity of both -ness and -ity), as well as to perform the same analysis for multiple unrelated corpora. However, to keep things simple, we will explain the case of a single corpus and single dataset. In this case:
- You add one row to the table corpus, pick an identifier for your corpus (corpuscode), and use this identifier in all other tables that contain the corpuscode field.
- You add one row to the table dataset, pick an identifier for your dataset (datasetcode), and use this identifier in all other tables that contain the datasetcode field.
Now we are ready to specify the samples and collections:
- Each row in the table sample describes one sample. There are fields for the identifier of the sample (samplecode), for a human-readable description, and for the total number of words in the sample. The word count is needed so that types2 can relate the type richness with the size of the collection in running words. There is also an optional field link for a URL that provides further information on the sample – this link will appear in the web frontend.
- Each row in the table collection describes one collection. There are fields for the identifier of the collection (collectioncode) and for a human-readable description. There is also a field groupcode that you can use to group related collections together for easier access in the web user interface.
- To specify which samples constitute which collection, you add collectioncode–samplecode pairs to the table sample_collection.
Finally, we list all occurrences of the tokens:
- Each row in the table token contains the following fields: samplecode, tokencode, and tokencount. A row with samplecode = x, tokencode = y, and tokencount = n specifies that sample x contains n occurrences of token y.
This is all that we need for the backend to make its analysis. By default, it will analyse the number of types, but you can also request additional data analysis by adding any of the following codes to the table defaultstat:
type-word
: analyse types / running wordstype-token
: analyse types / tokenshapax-word
: analyse hapaxes / running wordshapax-token
: analyse hapaxes / tokenstoken-word
: analyse tokens / running words.
To make it easier to explore the results in the frontend, you can also provide more information on the occurrences of the tokens. To that end, you can optionally fill in the table context, in which you can list the occurrences in a format familiar from concordance tools.
Case study: BNC
Let us now have a closer look at how we have populated the database in our BNC case study. While reading this section, you can also explore the data in the web interface, or you can download the entire database from the following Git repositories:
In the Git repository, the directory empty
contains the database template, bnc-input
contains the database with all input data ready for analysis, and bnc-output
shows what the database looks like after running the backend.
We combine data from both BNCweb and MorphoQuantics. The process is semi-automatic: We first wrote a script that tries to match BNCweb search results with MorphoQuantics data, as well as possible. After this step, we were left with ambiguities, which were manually resolved by pruning and normalizing data in Excel. Finally, our scripts combined the input from all three data sources – BNCweb, MorphoQuantics, and Excel – and used it to populate the types2 database. You can find the Python scripts that we used at the following repositories:
Most of the code is related to the task of making the best possible use of MorphoQuantics data automatically. In brief, for each POS-tagged word, we compare the numbers in MorphoQuantics data with the total number of hits in BNCweb search results, and if these are (almost) identical, we will use the MorphoQuantics classification. Once the data is in a clean, tabular form, the remaining task of inserting it in the correct database tables is straightforward.
In what follows, we will show examples of precisely what data we have in each database table.
Table corpus
In this study, we use just one corpus, the demographically sampled spoken component of the BNC. We will use the code bnc-spoken-demo
for this corpus.
| corpuscode |
|---|
| bnc-spoken-demo |
Table dataset
We want to explore both -er and -or separately. Furthermore, we want to see statistics for each suffix in general, as well as for their animate (person
) and inanimate (thing
) senses separately. Hence in the end we will have six different datasets. Note that all data from e.g. er-person
and er-thing
will also be duplicated in the dataset er
.
| corpuscode | datasetcode |
|---|---|
| bnc-spoken-demo | er |
| bnc-spoken-demo | er-person |
| bnc-spoken-demo | er-thing |
| bnc-spoken-demo | or |
| bnc-spoken-demo | or-person |
| bnc-spoken-demo | or-thing |
Table sample
The key challenge with the spoken BNC data is to define meaningful samples. On the one hand, each sample should contain spoken language from only one person, and the samples should be meaningful entities that are preferably as independent from each other as possible. On the other hand, natural dialogue by its very nature interleaves language spoken by different people.
In the end, we have chosen to define our samples so that one sample corresponds to one speaker. For example, our sample PS007
consists of everything that was recorded from the informant whose speaker ID in the BNC is PS007
. As we are interested in sociolinguistic aspects, we have discarded speakers whose gender or social class was unknown.
For the purposes of analysing types vs. running words, it is necessary to have information on word counts for each of the speakers. The descriptions and hyperlinks are optional information, but this information makes it much easier to explore and interpret results in the web frontend.
| corpuscode | samplecode | wordcount | description | link |
|---|---|---|---|---|
| bnc-spoken-demo | PS007 | 6987 | AB Male 60- | http://bncweb.lancs.ac.uk/cgi-binbncXML/speakerInfo_new.pl?text=KB0&spid=PS007&urlTest=yes |
| bnc-spoken-demo | PS01A | 13306 | DE Male 45-59 | http://bncweb.lancs.ac.uk/cgi-binbncXML/speakerInfo_new.pl?text=KB1&spid=PS01A&urlTest=yes |
| bnc-spoken-demo | PS01B | 12587 | DE Female 45-59 | http://bncweb.lancs.ac.uk/cgi-binbncXML/speakerInfo_new.pl?text=KB1&spid=PS01B&urlTest=yes |
| bnc-spoken-demo | PS01D | 3993 | DE Female 15-24 | http://bncweb.lancs.ac.uk/cgi-binbncXML/speakerInfo_new.pl?text=KB1&spid=PS01D&urlTest=yes |
| bnc-spoken-demo | PS01T | 7025 | DE Male 60- | http://bncweb.lancs.ac.uk/cgi-binbncXML/speakerInfo_new.pl?text=KB2&spid=PS01T&urlTest=yes |
| bnc-spoken-demo | PS01V | 16711 | DE Female 60- | http://bncweb.lancs.ac.uk/cgi-binbncXML/speakerInfo_new.pl?text=KB2&spid=PS01V&urlTest=yes |
| bnc-spoken-demo | PS028 | 1442 | C2 Male 15-24 | http://bncweb.lancs.ac.uk/cgi-binbncXML/speakerInfo_new.pl?text=KB5&spid=PS028&urlTest=yes |
| bnc-spoken-demo | PS029 | 8397 | DE Female 25-34 | http://bncweb.lancs.ac.uk/cgi-binbncXML/speakerInfo_new.pl?text=KB6&spid=PS029&urlTest=yes |
| bnc-spoken-demo | PS02A | 221 | DE Male 25-34 | http://bncweb.lancs.ac.uk/cgi-binbncXML/speakerInfo_new.pl?text=KB6&spid=PS02A&urlTest=yes |
| bnc-spoken-demo | PS02F | 406 | DE Male -14 | http://bncweb.lancs.ac.uk/cgi-binbncXML/speakerInfo_new.pl?text=KB6&spid=PS02F&urlTest=yes |
| … | ||||
Table collection
Our goal is to explore two social factors: gender and social class. To this end, we define four collections: women (Female
), men (Male
), higher social classes (AB+C1
), and lower social classes (C2+DE
). For example, in the collection C2+DE
we have put together all speakers whose social class in the BNC metadata was either C2
or DE
– this roughly corresponds to the working class.
We use the groupcode
column to group together those collections that are related to gender, and those collections that are related to social class. This is mainly for convenience so that we can more easily explore either of these dimensions separately in the web frontend.
| corpuscode | collectioncode | groupcode |
|---|---|---|
| bnc-spoken-demo | Female | gender |
| bnc-spoken-demo | Male | gender |
| bnc-spoken-demo | AB+C1 | social class |
| bnc-spoken-demo | C2+DE | social class |
Table sample_collection
For example, the informant PS007
was a man with social class AB
in the BNC metadata. Hence in our database, the sample PS007
will be in two collections: Male
and AB+C1
. Hence we insert two rows in the table sample_collection
.
| corpuscode | samplecode | collectioncode |
|---|---|---|
| bnc-spoken-demo | PS007 | AB+C1 |
| bnc-spoken-demo | PS007 | Male |
| bnc-spoken-demo | PS01A | C2+DE |
| bnc-spoken-demo | PS01A | Male |
| bnc-spoken-demo | PS01B | C2+DE |
| bnc-spoken-demo | PS01B | Female |
| bnc-spoken-demo | PS01D | C2+DE |
| bnc-spoken-demo | PS01D | Female |
| bnc-spoken-demo | PS01T | C2+DE |
| bnc-spoken-demo | PS01T | Male |
| … | ||
Table token
For each sample, we extract all relevant occurrences of the words formed with -er or -or. The table token
gives an overview of the findings. For example, the speaker PS007
used the word brainstormer once and the word computer four times in total.
| corpuscode | samplecode | datasetcode | tokencode | tokencount |
|---|---|---|---|---|
| bnc-spoken-demo | PS007 | er | brainstormer | 1 |
| bnc-spoken-demo | PS007 | er | carrier | 1 |
| bnc-spoken-demo | PS007 | er | checker | 1 |
| bnc-spoken-demo | PS007 | er | computer | 4 |
| bnc-spoken-demo | PS007 | er | copier | 1 |
| bnc-spoken-demo | PS007 | er | farmer | 1 |
| bnc-spoken-demo | PS007 | er | freezer | 1 |
| bnc-spoken-demo | PS007 | er | lever | 1 |
| bnc-spoken-demo | PS007 | er | passenger | 2 |
| bnc-spoken-demo | PS007 | er | preacher | 2 |
| … | ||||
Table context
Our backend only needs the summary information that is given in the table token
, but for the benefit of a user exploring the results in the web frontend, we also add more detailed information on each occurrence of each token. For example, while we had just one row in the table token
for the word computer in sample PS007
, there will be four distinct rows in the table context
, one for each occurrence.
| corpuscode | samplecode | datasetcode | tokencode | before | word | after | link |
|---|---|---|---|---|---|---|---|
| bnc-spoken-demo | PS007 | er | brainstormer | So , in the next elders meeting we used a management technique , | brainstormers | think the say what you think . | http://bncweb.lancs.ac.uk/cgi-binbncXML/context.pl?text=KB0&qname=nosol&refnum=0&theData=0&len=0&showTheTag=0&color=0&begin=1078&spids=1&interval=11&first=yes&urlTest=yes |
| bnc-spoken-demo | PS007 | er | carrier | No , I 'll put them in this , why use up your | carrier | bags , anyhow this is an easier way to carry | http://bncweb.lancs.ac.uk/cgi-binbncXML/context.pl?text=KB0&qname=nosol&refnum=0&theData=0&len=0&showTheTag=0&color=0&begin=199&spids=1&interval=11&first=yes&urlTest=yes |
| bnc-spoken-demo | PS007 | er | checker | And a computer you 've got a | spellchecker | . | http://bncweb.lancs.ac.uk/cgi-binbncXML/context.pl?text=KB0&qname=nosol&refnum=0&theData=0&len=0&showTheTag=0&color=0&begin=3303&spids=1&interval=11&first=yes&urlTest=yes |
| bnc-spoken-demo | PS007 | er | computer | We just want a bit of information about setting up a | computer | . | http://bncweb.lancs.ac.uk/cgi-binbncXML/context.pl?text=KB0&qname=nosol&refnum=0&theData=0&len=0&showTheTag=0&color=0&begin=2877&spids=1&interval=11&first=yes&urlTest=yes |
| bnc-spoken-demo | PS007 | er | computer | A | computer | and a printer , mm . | http://bncweb.lancs.ac.uk/cgi-binbncXML/context.pl?text=KB0&qname=nosol&refnum=0&theData=0&len=0&showTheTag=0&color=0&begin=3321&spids=1&interval=11&first=yes&urlTest=yes |
| bnc-spoken-demo | PS007 | er | computer | You see the beauty of the beauty of the | computer | or wordprocessor compared to an electronic typewriter is you can finish your document and then do your spellcheck . | http://bncweb.lancs.ac.uk/cgi-binbncXML/context.pl?text=KB0&qname=nosol&refnum=0&theData=0&len=0&showTheTag=0&color=0&begin=3325&spids=1&interval=11&first=yes&urlTest=yes |
| bnc-spoken-demo | PS007 | er | computer | And a | computer | you 've got a spellchecker . | http://bncweb.lancs.ac.uk/cgi-binbncXML/context.pl?text=KB0&qname=nosol&refnum=0&theData=0&len=0&showTheTag=0&color=0&begin=3303&spids=1&interval=11&first=yes&urlTest=yes |
| bnc-spoken-demo | PS007 | er | copier | Oh I see , it 's not an ordinary | photocopier | ? | http://bncweb.lancs.ac.uk/cgi-binbncXML/context.pl?text=KB0&qname=nosol&refnum=0&theData=0&len=0&showTheTag=0&color=0&begin=3237&spids=1&interval=11&first=yes&urlTest=yes |
| bnc-spoken-demo | PS007 | er | farmer | Because there are worries that it 's going to er , effect the outcome of this mad ref , referendum , you know they the | farmers | are sort of desperate and they think they need government help and they think they would n't get it because of the black government so | http://bncweb.lancs.ac.uk/cgi-binbncXML/context.pl?text=KB0&qname=nosol&refnum=0&theData=0&len=0&showTheTag=0&color=0&begin=620&spids=1&interval=11&first=yes&urlTest=yes |
| bnc-spoken-demo | PS007 | er | freezer | Er , half a pound will do , no give me a pound , I 'll put them in the | freezer | and | http://bncweb.lancs.ac.uk/cgi-binbncXML/context.pl?text=KB0&qname=nosol&refnum=0&theData=0&len=0&showTheTag=0&color=0&begin=186&spids=1&interval=11&first=yes&urlTest=yes |
| … | |||||||
Table defaultstat
In this study, we are interested in exploring all the statistics that our software supports. Hence we add the following codes to the table defaultstat
.
| statcode |
|---|
| hapax-token |
| hapax-word |
| token-word |
| type-token |
| type-word |
Case study: CEEC
Let us now discuss briefly the key technical aspects of the CEEC example. The database for this study is also available in the following Git repositories:
The directory ceec-input
contains the database with all input data ready for analysis, and ceec-output
shows the results after running the backend. As noted before, you can explore the results online.
We will not discuss all database tables here, as the basic idea is similar to that of the BNC study. However, we will highlight some key differences.
Table corpus
In this database, we define two different corpora. The source data is the same in both cases, but the way in which the text is divided into samples varies.
In the corpus ceec-1680-1800
we use the fairly natural choice that a sample consists of all letters written by one person during a 20-year period; this enables us to study how the diversity of the language varies between different writers and how it varies between different time periods.
In the corpus ceec-1680-1800-relcode
we have further divided the samples based on the relationship code in the CEEC metadata. This code describes the relationship between the sender and recipient of the letter. This corpus hence makes it possible to study how the relationship influences the way in which language is used in letters.
| corpuscode | description |
|---|---|
| ceec-1680-1800 | CEEC & CEECE, 1680-1800, sample = letters with a certain sender & period |
| ceec-1680-1800-relcode | CEEC & CEECE, 1680-1800, sample = letters with a certain sender & period & relcode |
Table sample
In the corpus ceec-1680-1800
, each sample is named after the person code in the CEEC metadata, followed by a number that refers to a 20-year period. We link each sample to information on the person in the CEECer web interface.
| corpuscode | samplecode | wordcount | link |
|---|---|---|---|
| ceec-1680-1800 | A1HATTON-1680 | 889 | http://h89.it.helsinki.fi/ceec/func/personFunc.jsp?personID=A1HATTON |
| ceec-1680-1800 | A1MONTAGUE-1680 | 1517 | http://h89.it.helsinki.fi/ceec/func/personFunc.jsp?personID=A1MONTAGUE |
| ceec-1680-1800 | A2HATTON-1680 | 478 | http://h89.it.helsinki.fi/ceec/func/personFunc.jsp?personID=A2HATTON |
| ceec-1680-1800 | A2HATTON-1700 | 287 | http://h89.it.helsinki.fi/ceec/func/personFunc.jsp?personID=A2HATTON |
| ceec-1680-1800 | A2MONTAGUE-1680 | 473 | http://h89.it.helsinki.fi/ceec/func/personFunc.jsp?personID=A2MONTAGUE |
| ceec-1680-1800 | AAHANOVER-1780 | 3797 | http://h89.it.helsinki.fi/ceec/func/personFunc.jsp?personID=AAHANOVER |
| ceec-1680-1800 | ABANKS-1700 | 266 | http://h89.it.helsinki.fi/ceec/func/personFunc.jsp?personID=ABANKS |
| ceec-1680-1800 | ABATHURST-1700 | 7505 | http://h89.it.helsinki.fi/ceec/func/personFunc.jsp?personID=ABATHURST |
| ceec-1680-1800 | ABATHURST-1720 | 8891 | http://h89.it.helsinki.fi/ceec/func/personFunc.jsp?personID=ABATHURST |
| ceec-1680-1800 | ACLARK-1760 | 215 | http://h89.it.helsinki.fi/ceec/func/personFunc.jsp?personID=ACLARK |
| … | |||
Table context
The following glimpse at the table context
illustrates the way in which tokens are normalized in the CEEC study. Here the word
column contains the token as it was written in the corpus, while tokencode
gives the normalized version that will be used in the analysis. Here the normalization process was mostly manual work: we extracted raw concordances from the corpus into Excel and edited and pruned them there. The final results were then combined with the CEEC metadata and imported into the database.
| corpuscode | samplecode | datasetcode | tokencode | before | word | after | link |
|---|---|---|---|---|---|---|---|
| ceec-1680-1800 | A1MONTAGUE-1680 | ity | opportunity | Epsom watters, that he might not grow to fatt, and to buy some little mourninge, made mee take this | oppertunitie | . The towne is very | http://h89.it.helsinki.fi/ceec/func/letterFunc.jsp?letterID=HATTON_075 |
| ceec-1680-1800 | A1MONTAGUE-1680 | ity | parity | was unsattisfied, except those that out of favour to some of the | parity | might wish it orther wayes. The scandall laid upon y=e= wittnesses was much taken offe, and, untill I heare w=t= y=e= L=ds= have done, I will say noe more as to my oppinion. I | http://h89.it.helsinki.fi/ceec/func/letterFunc.jsp?letterID=HATTON_072 |
| ceec-1680-1800 | A1MONTAGUE-1680 | ity | quality | Here is strange neues from France. A great many people of the best | quality | accused for pois[{on{]ing. Madame de Sowison (Madame Mazerine sister) hath made her escape. She is said to have bine the death of her husband. Severall more w=ch= was | http://h89.it.helsinki.fi/ceec/func/letterFunc.jsp?letterID=HATTON_067 |
| ceec-1680-1800 | A1MONTAGUE-1680 | ness | business | mee. I came w=th= my L=d= last weeke to this place, and designe w=th=ing two dayes to returne to Leez. His | bisnes | was to take Epsom watters, that he might not grow to fatt, and to buy some little mourninge, made mee take this oppertunitie. The towne | http://h89.it.helsinki.fi/ceec/func/letterFunc.jsp?letterID=HATTON_075 |
| ceec-1680-1800 | A1MONTAGUE-1680 | ness | illness | relations out of this family, I cannot but be frighted w=th= the least rumore of | illness | in one soe very neare unto mee, and for whom I have soe tender an affectione, w=ch= she justly merritts from mee. | http://h89.it.helsinki.fi/ceec/func/letterFunc.jsp?letterID=HATTON_075 |
| ceec-1680-1800 | A1MONTAGUE-1680 | ness | kindness | will gaine a perfitt health before she proove w=th= childe. Your L=dsp= care and | kindness | she hath soe often founde, that all must be fully sattisfied nothing could bee wantinge was to be had in order to helpe. Wee have lost lately soe many relations | http://h89.it.helsinki.fi/ceec/func/letterFunc.jsp?letterID=HATTON_075 |
| ceec-1680-1800 | A1MONTAGUE-1680 | ness | witness | parity might wish it orther wayes. The scandall laid upon y=e= | wittnesses | was much taken offe, and, untill I heare w=t= y=e= L=ds= have done, I will say noe more as to my oppinion. I cannot but looke upon it as a wonderful providence of God Allmighty | http://h89.it.helsinki.fi/ceec/func/letterFunc.jsp?letterID=HATTON_072 |
| ceec-1680-1800 | A2HATTON-1680 | ity | quality | Ibbings who danced at Lincolns Inn Feild and is lately dead. But as y=e= | quallity | of y=e= Ladys that dance at Court is not to be compared w=th= so mean a pe | http://h89.it.helsinki.fi/ceec/func/letterFunc.jsp?letterID=HATTON2_072 |
| ceec-1680-1800 | A2HATTON-1680 | ness | bigness | hear in them y=t= a good one cant cost les then 60 pound, and y=t= monstros | bignes | w=th= his lettle face did not look so well. I hear Lady Banbery is dead, a | http://h89.it.helsinki.fi/ceec/func/letterFunc.jsp?letterID=HATTON2_073 |
| ceec-1680-1800 | A2HATTON-1700 | ness | business | married, which I think should make this young lady afraid. I have so much | buisness | here y=t= I hope my Lady will excuse me till next post. I beg my duty to h | http://h89.it.helsinki.fi/ceec/func/letterFunc.jsp?letterID=HATTON2_075 |
| … | |||||||
Analysis
The previous sections have given two examples of how to populate the database. Now let us assume that we have a database ready for analysis in the file db/types.sqlite
, which is the default location used by the types2 backend. From the user’s perspective, the remaining steps are easy – just run the following two commands:
bin/types-run
bin/types-web
The first command will read the input from the database, do the data analysis, and write the results back to the database. You will find lots of new data in the tables log
, result_curve
, result_curve_point
, result_p
, and result_q
. The second command will construct the web frontend. Now you can open the file web/index.html
in your web browser.
Performance and speeding it up
While running the backend is easy for the user once we have the data in the database, it is not that easy for the computer. The tool relies on Monte Carlo permutation testing (Mitzenmacher & Upfal 2005: 252), and with the default parameters, it constructs ten million random permutations of each corpus, for each data set. While the implementation is highly optimized C code, this inevitably takes a fair amount of time.
With our sample data sets, on a modern desktop computer, both the BNC data and the CEEC data took some 5–6 minutes to process. To speed things up, you can use a high-end computer with a multi-core processor – the tool automatically parallelizes computations for any number of processors.
However, when you are setting up your database, it is convenient to perform a quick, less thorough computation to make sure that you have configured everything correctly. To this end, you can use smaller values for the citer
and piter
parameters:
bin/types-run --citer=100000 --piter=100000
bin/types-web
With these parameters, we only construct some 100,000 random permutations. It may not be a good idea to count on the results that you obtain this way – especially the estimates of the p-values may be a bit off – but you can nevertheless get a rough approximation of the results that you will eventually get. Once you are happy with your database, you can recalculate everything with the default settings:
bin/types-run --recalc
bin/types-web
A complete example
We conclude with a complete example of how to download the software and sample data, how to compile and run it, and how to start to explore the results. This example was tested on Mac OS X, but the usage on Linux is similar.
git clone https://github.com/suomela/types.git
git clone https://github.com/suomela/types-examples.git
cd types
./config
make
mkdir db
cp ../types-examples/bnc-input/db/types.sqlite db/types.sqlite
bin/types-run --citer=100000 --piter=100000
bin/types-web
open web/index.html
You can get more information on the usage of the backend with the command line switch --help
:
bin/types-run --help
bin/types-web --help
Acknowledgements
The authors wish to thank CSC – IT Center for Science, Finland, for computational resources. This work was supported in part by the Academy of Finland grant 276349 to the project ‘Reassessing language change: the challenge of real time’.
Data cited herein have been extracted from the British National Corpus, distributed by the University of Oxford on behalf of the BNC Consortium. All rights in the texts cited are reserved.
References
BNC = The British National Corpus, version 3 (BNC XML edition). 2007. Distributed by Oxford University Computing Services on behalf of the BNC Consortium. http://www.natcorp.ox.ac.uk
CEEC = Corpora of Early English Correspondence. Compiled by Terttu Nevalainen, Helena Raumolin-Brunberg et al. at the Department of Modern Languages, University of Helsinki. https://varieng.helsinki.fi/CoRD/corpora/CEEC/
Mitzenmacher, Michael & Eli Upfal. 2005. Probability and computing: randomized algorithms and probabilistic analysis. Cambridge: Cambridge University Press.
Säily, Tanja & Jukka Suomela. 2016. types2: Exploring word-frequency differences in corpora. https://jukkasuomela.fi/types2-d2e/
Saito, Mutsuo & Makoto Matsumoto. 2008. SIMD-oriented fast Mersenne twister: a 128-bit pseudorandom number generator. In Alexander Keller, Stefan Heinrich & Harald Niederreiter (eds.), Proc. 7th international conference on Monte Carlo and quasi-Monte Carlo methods in scientific computing (MCQMC 2006), 607–622. Berlin: Springer. doi:10.1007/978-3-540-74496-2_36
Suomela, Jukka. 2016. types2: type and hapax accumulation curves. Computer program. https://jukkasuomela.fi/types2/